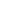Healthcare App Development Services
Healthcare App Development Services
 Real Estate Web Development Services
Real Estate Web Development Services
 E-Commerce App Development Services
E-Commerce App Development Services E-Commerce Web Development Services
E-Commerce Web Development Services Blockchain E-commerce Development Company
Blockchain E-commerce Development Company
 Fintech App Development Services
Fintech App Development Services Fintech Web Development
Fintech Web Development Blockchain Fintech Development Company
Blockchain Fintech Development Company
 E-Learning App Development Services
E-Learning App Development Services
 Restaurant App Development Company
Restaurant App Development Company
 Mobile Game Development Company
Mobile Game Development Company
 Travel App Development Company
Travel App Development Company
 Automotive Web Design
Automotive Web Design
 AI Traffic Management System
AI Traffic Management System
 AI Inventory Management Software
AI Inventory Management Software
 AI Development Company
AI Development Company  ChatGPT integration services
ChatGPT integration services  AI Integration Services
AI Integration Services  Generative AI Development Services
Generative AI Development Services  Natural Language Processing Company
Natural Language Processing Company Machine Learning Development
Machine Learning Development  Machine learning consulting services
Machine learning consulting services  Blockchain Development
Blockchain Development  Blockchain Software Development
Blockchain Software Development  Smart Contract Development Company
Smart Contract Development Company  NFT Marketplace Development Services
NFT Marketplace Development Services  Asset Tokenization Company
Asset Tokenization Company DeFi Wallet Development Company
DeFi Wallet Development Company Mobile App Development
Mobile App Development  IOS App Development
IOS App Development  Android App Development
Android App Development  Cross-Platform App Development
Cross-Platform App Development  Augmented Reality (AR) App Development
Augmented Reality (AR) App Development  Virtual Reality (VR) App Development
Virtual Reality (VR) App Development  Web App Development
Web App Development  SaaS App Development
SaaS App Development Flutter
Flutter  React Native
React Native  Swift (IOS)
Swift (IOS)  Kotlin (Android)
Kotlin (Android)  Mean Stack Development
Mean Stack Development  AngularJS Development
AngularJS Development  MongoDB Development
MongoDB Development  Nodejs Development
Nodejs Development  Database Development
Database Development Ruby on Rails Development
Ruby on Rails Development Expressjs Development
Expressjs Development  Full Stack Development
Full Stack Development  Web Development Services
Web Development Services  Laravel Development
Laravel Development  LAMP Development
LAMP Development  Custom PHP Development
Custom PHP Development  .Net Development
.Net Development  User Experience Design Services
User Experience Design Services  User Interface Design Services
User Interface Design Services  Automated Testing
Automated Testing  Manual Testing
Manual Testing  Digital Marketing Services
Digital Marketing Services 
 Ride-Sharing And Taxi Services
Ride-Sharing And Taxi Services Food Delivery Services
Food Delivery Services Grocery Delivery Services
Grocery Delivery Services Transportation And Logistics
Transportation And Logistics Car Wash App
Car Wash App Home Services App
Home Services App ERP Development Services
ERP Development Services CMS Development Services
CMS Development Services LMS Development
LMS Development CRM Development
CRM Development DevOps Development Services
DevOps Development Services AI Business Solutions
AI Business Solutions AI Cloud Solutions
AI Cloud Solutions AI Chatbot Development
AI Chatbot Development API Development
API Development Blockchain Product Development
Blockchain Product Development Cryptocurrency Wallet Development
Cryptocurrency Wallet Development About Talentelgia
About Talentelgia  Our Team
Our Team  Our Culture
Our Culture 
 Healthcare App Development Services
Healthcare App Development Services Real Estate Web Development Services
Real Estate Web Development Services E-Commerce App Development Services
E-Commerce App Development Services E-Commerce Web Development Services
E-Commerce Web Development Services Blockchain E-commerce
Development Company
Blockchain E-commerce
Development Company Fintech App Development Services
Fintech App Development Services Finance Web Development
Finance Web Development Blockchain Fintech
Development Company
Blockchain Fintech
Development Company E-Learning App Development Services
E-Learning App Development Services Restaurant App Development Company
Restaurant App Development Company Mobile Game Development Company
Mobile Game Development Company Travel App Development Company
Travel App Development Company Automotive Web Design
Automotive Web Design AI Traffic Management System
AI Traffic Management System AI Inventory Management Software
AI Inventory Management Software AI Development Company
AI Development Company ChatGPT integration services
ChatGPT integration services AI Integration Services
AI Integration Services Machine Learning Development
Machine Learning Development Machine learning consulting services
Machine learning consulting services Blockchain Development
Blockchain Development Blockchain Software Development
Blockchain Software Development Smart contract development company
Smart contract development company NFT marketplace development services
NFT marketplace development services IOS App Development
IOS App Development Android App Development
Android App Development Cross-Platform App Development
Cross-Platform App Development Augmented Reality (AR) App
Development
Augmented Reality (AR) App
Development Virtual Reality (VR) App Development
Virtual Reality (VR) App Development Web App Development
Web App Development Flutter
Flutter React
Native
React
Native Swift
(IOS)
Swift
(IOS) Kotlin (Android)
Kotlin (Android) MEAN Stack Development
MEAN Stack Development AngularJS Development
AngularJS Development MongoDB Development
MongoDB Development Nodejs Development
Nodejs Development Database development services
Database development services Ruby on Rails Development services
Ruby on Rails Development services Expressjs Development
Expressjs Development Full Stack Development
Full Stack Development Web Development Services
Web Development Services Laravel Development
Laravel Development LAMP
Development
LAMP
Development Custom PHP Development
Custom PHP Development User Experience Design Services
User Experience Design Services User Interface Design Services
User Interface Design Services Automated Testing
Automated Testing Manual
Testing
Manual
Testing About Talentelgia
About Talentelgia Our Team
Our Team Our Culture
Our Culture
Training a large language model (LLM) could be a formidable task that requires a massive amount of computational power, data, human hours, etc. As more universities, institutions, and researchers attempt to train their own models, now is the time for the AI research and development community to step up and guide them towards safer, cheaper, and greener LLM training practices. In other words, the tools need to be efficient, which minimizes the time and cost of training, and easy to use so that researchers can work as fast as possible and have time to devote to other aspects of their work.
But have you ever caught yourself asking how tools like ChatGPT or Google’s Gemini are actually built? Or how to create an LLM? Behind these excellent AI tools is a complicated but fascinating model training, data preparation, and fine-tuning of LLM. Although the whole process looks like rocket science reserved for big labs, you can learn to build a tiny version from scratch for yourself. And with proper step-by-step instructions, you should be able to know how to train an LLM. Keep reading this blog to know more.
Understanding Large Language Models (LLMs): Types and Importance
There has been a remarkable shift in the world of Natural Language Processing (NLP) in recent years. Most of this change comes from the rise of new large language models (LLMs). These models are driven by the incredible technological advances in deep learning and artificial intelligence. They’re designed to read, analyze, and produce textual content, which is quite similar to the human-like behavior of communication.
Large Language Models (LLMs) have been trained on a massive treasure chest of linguistic knowledge that serves as their input for ML applications. In this blog, we’ll jump right into how to train an LLM, its types, and its benefits. Let’s get set and go! To that end, here’s a breakdown of what you need to know as part of this training:
Types of Training Large Language Models (LLMs)
As we have already discussed above, LLMs have changed how humans interact with AI, powering everything from AI chatbots to content development to technical troubleshooting. Still, LLMs stumble over industry lingo, niche reports, or company manuals or documentation that is outside their generic training. So, how to create an LLM and how do you give them the inside knowledge that they need? The answer is simple— train a model of your own! We will guide you through different types of training LLMs in the following:
1. Pre-Training LLM
The first phase in LLM training is called pretraining. The model is pre-trained on an enormous amount of unlabelled text during pre-training. It’s all about predicting the next word in a sentence, or filling in a gap of masked words from a sequence. This task of unsupervised learning is helpful for the model to capture the statistical regularities and structures of language.
Pre-training supplies the LLM with prior knowledge of grammar, syntax, and semantics. It enables the model to remember word relationships. It also gives it a strong base for understanding language.
2. Fine-Tuning LLM
Fine-tuning LLM involves adjusting a pre-trained model, which is done by training it on data relevant to a specific task. To improve its effectiveness, the model goes through specialized training that enables it to adjust its parameters and gain some mastery of understanding domain-specific patterns.
This helps the model comprehend details that are important for generating accurate outputs. By providing the model with specific contexts and examples, you enable it to respond more accurately and appropriately.
LLM fine-tuning is further categorized in several ways, depending on its primary focus and particular objectives:
- Supervised Fine-Tuning: This is the easiest and most popular method of fine-tuning. The model is trained on a labeled task dataset. With a specified aim of performing like text classification or named entity recognition. For example, training models using a dataset that comprises text samples and labels reflecting their respective sentiments, annotated for sentiment analysis.
- Few-Shot Learning: In some cases, it is pretty impractical to gather a large labeled dataset. Few-shot learning attempts to solve this problem by providing few examples or “shots” of the task within the input prompts. This enables the model to better understand the context of the task at hand with minimal fine-tuning.
- Transfer Learning: Although all types of fine-tuning are categorized under transfer learning. This class is intended to give the model the ability to perform tasks from what it was trained on initially. The idea here is to utilize the insights gained from an extensive and generic dataset to perform more focused or related tasks.
- Domain-Specific Fine-Tuning: This type of fine-tuning works with a model to help it understand and create texts related to a specific field or industry. The model is trained using text from the specific domain in order to improve its contextual understanding and cognitive skills on domain-specific tasks. For example, when designing a medical app chatbot, the model would be tailored through training sessions involving medical documents so that its language comprehension skills are better adapted to the health sector.
Why Fine-Tuning LLM Is Important?
Nowadays, while the majority of the LLM models achieve strong global performance, they still struggle with more task-specific problems. The fine-tuning process brings substantial benefits, such as reduced computation costs and using the latest models without the need to design a new model from scratch. With transformers, anyone can access a large pool of pre-trained models based on a wide range of tasks. Fine-tuning these models is a crucial step in improving their performance in particular tasks such as sentiment analysis, question & answering (Q & A), or summarizing documents by training them with new task-specific examples with increased precision.
Fine-tuning LLM focuses on the specific model’s performance, thus enhancing its practical utility. This process is critical for customizing an existing model to address a specific need or area. Deciding whether to perform fine-tuning depends on one’s objectives, which usually differ depending on the domain or use cases.
Some popular LLMs are ChatGPT, Gemini, Bing Chat, Llama, and Copilot. Their applications include content production for business or schooling, extraction of information from online sources, chatting with users to answer their inquiries, and much more. However, these LLMs also present challenges, such as threats to privacy concerns or less accurate and biased results. You can mitigate these challenges by training the LLM on your datasets.
Step-by-Step Guide on How To Fine-Tune an LLM
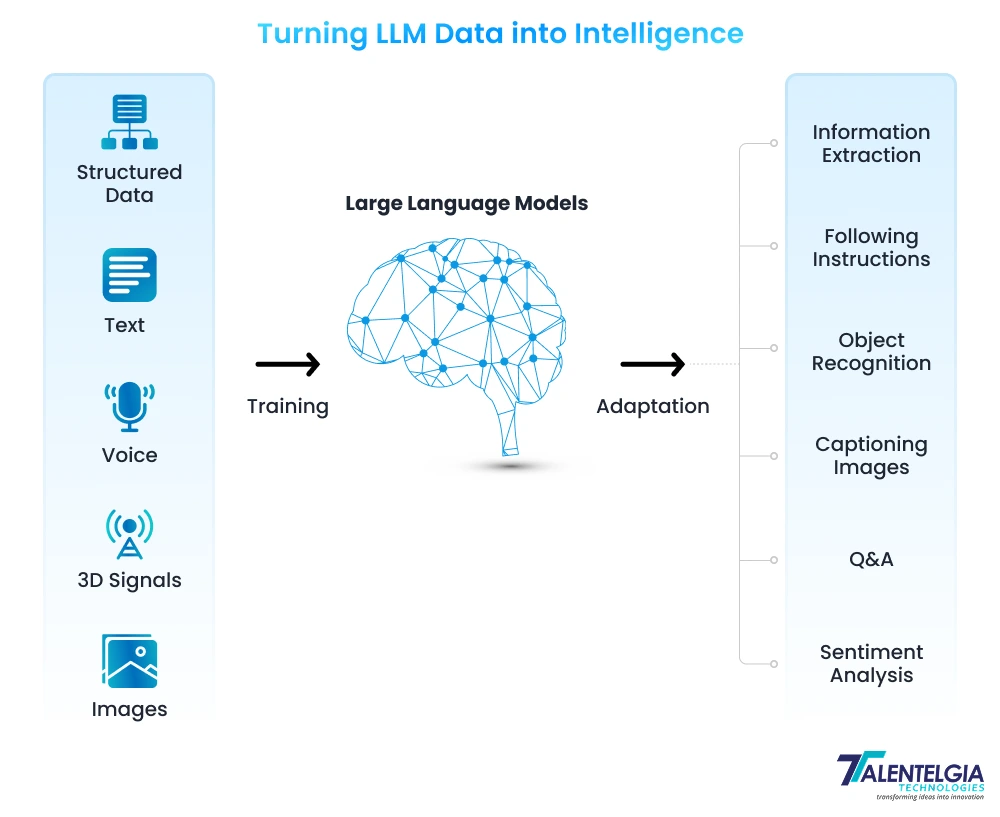
We know that Fine-tuning LLM means taking a pre-trained model and fine-tuning its parameters for a particular task by training it on our own task-specific dataset. So, let’s exemplify this concept in detail by understanding how to fine-tune LLM with an 8-step-by-step process:
1. Define Your Business Objectives and Goals
Set specific objectives and goals for which you intend to use the LLM trained on your data. These could include crafting tailored content, responding to customer queries, drafting legal documents, etc. Defining clear objectives not only helps you focus on what you want to achieve but also estimates the computational resources and budget designated towards training LLMs.
2. Choose a Pre-Trained Model or Dataset
The right LLM you choose mainly depends on the type of tasks, available computational resources, and access to a large amount of training data. Although pre-trained models have a good head start and can be loaded with code in no time, a custom model through fine-tuning an LLM yields higher accuracy. Selecting the right LLM model architecture directly impacts cost efficiency and the quality of responses generated. Some options include:
- OpenAI’s GPT Models: Flexible and ideal for API-based personalization
- LLaMA by Meta: Open-source and versatile
- Google’s PaLM: Designed for massive-scale training procedures
- Falcon, Mistral, or BLOOM: Open-source alternative for in-house deployment
For more light-weight LLm models, take a look at GPT-3.5, Falcon-7B, or LLaMA 2-7B
3. Data Collection & Preparation
To create a dataset tailored for your training purposes on LLM, it is imperative that you first gather all information relevant to your field and bring it together in one location. Later, suitable data cleaning methods can be applied to turn this data into a standard form.
An LLM’s optimum performance relies on high-quality training data; therefore, the model requires special attention when collecting and preparing the training data. With well-organized datasets from credible sources, machine learning models can efficiently analyze data with remarkable accuracy and produce response outputs using human-like language during conversation. To collect and prepare your datasets, follow these guidelines:
- Data-Source Identification: Gather crucial data from various real-world sources, such as internal files, company repositories, structured databases, product manuals, customer and stakeholder interactions, etc.
- Pre-Process Data: Eliminate unnecessary data, duplicate entries, and characters. Transform data into a machine-readable format (e.g., JSON, PDF, HTML, CSV, or Microsoft data files). Tokenize sequences with byte pair encoding (BPE) for more efficient modelling.
- Quality Control of the Data: Enhance the quality of responses by properly tagging datasets to prevent biases and ensure accurate labelling of the datasets during the deduplication process.
4. Choose a Training Approach To Set Up an Environment
In this step, you have to configure the infrastructural surroundings by preparing the required hardware and software. While you’re at it, make sure you choose the best ML framework according to your preference, whether it’s Tensorflow, PyTorch, or Hugging Face. This is crucial because a well-suited framework will help train models effectively enough to meet your project’s requirements. When selecting the framework, you need to consider data size, computational resources, and budget.
Training process:
- Upload a pre-trained model (eg, LLaMA-2, GPT-3.5, or Falcon)
- Structure the dataset as pairs of inputs and outputs (prompts with corresponding responses).
- Perform instruction-based fine-tuning using PyTorch or TensorFlow
- Run training on GPUs (eg, H100 and A100) or TPUs
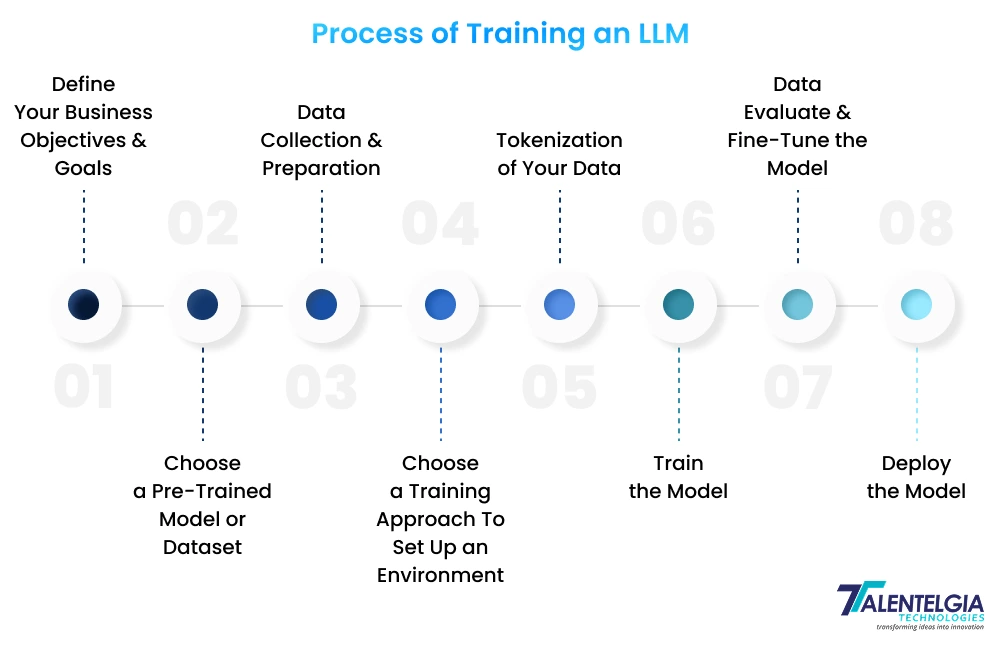
5. Tokenization of Your Data
LLM tokenization divides text data into smaller units, such as words, letters, characters, and punctuation. First, it’s crucial to transform the input text into tokens using a tokenizer and assign an index number to each token.
The indexed tokens are now fed into the model, which consists of an embedding layer along with some transformer blocks. The embedding layer enables the conversion of tokens into vectors, capturing their semantic meanings. Then we have the transformer block, which helps process these vector embeddings so that LLM can comprehend context for proper response generation.
6. Train The Model
Start training the model by setting the learning rate, batch size, number of epochs, and other hyperparameters. The model training phase may now be initiated. You will then be able to assess the predictions generated by the model alongside the predictions from your test data. Error minimization during the training of machine learning models can also be achieved through optimization techniques like stochastic gradient descent (SGD).
7. Evaluate & Fine-Tune the Model
It is necessary to track the performance of an LLM trained on your specific dataset. It can be tracked with evaluation metrics like accuracy, precision, F1-score, or recall. The performance of LLMs can also be optimized through further fine-tuning using smaller datasets specific to domains. Based on what you need, you can go for instruction fine-tuning, full fine-tuning, PEFT (parameter efficient fine-tuning), or any other method of your choice.
8. Deploy The Model
Finally, you can implement and deploy the LLM model that you have developed using your dataset into your business processes. This could mean connecting the LLM to your website or application. An API endpoint should be created for real-time integration of the LLM with any application.
For maintenance purposes, it is essential to track usage metrics while gathering feedback on the model and retraining it with new datasets, ensuring it remains accurate and relevant over time.
Conclusion
The journey towards fine-tuning Large Language Models (LLMs) offers a broad gateway to an entirely new realm of AI and its applications. This post aims to explain the advantages, techniques, and procedures needed to fully leverage such models. With the specific skills and knowledge, you can also train your desired LLM model adequately and experience its full potential.
To continue learning about effective strategies for fine-tuning LLM, we recommend you contact our AI development team. Our experts can share information on core training methods and recent relevant research.
















 Write us on:
Write us on:  Business queries:
Business queries:  HR:
HR: