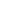Healthcare App Development Services
Healthcare App Development Services
 Real Estate Web Development Services
Real Estate Web Development Services
 E-Commerce App Development Services
E-Commerce App Development Services E-Commerce Web Development Services
E-Commerce Web Development Services Blockchain E-commerce Development Company
Blockchain E-commerce Development Company
 Fintech App Development Services
Fintech App Development Services Fintech Web Development
Fintech Web Development Blockchain Fintech Development Company
Blockchain Fintech Development Company
 E-Learning App Development Services
E-Learning App Development Services
 Restaurant App Development Company
Restaurant App Development Company
 Mobile Game Development Company
Mobile Game Development Company
 Travel App Development Company
Travel App Development Company
 Automotive Web Design
Automotive Web Design
 AI Traffic Management System
AI Traffic Management System
 AI Inventory Management Software
AI Inventory Management Software
 AI Software Development
AI Software Development  AI Development Company
AI Development Company  AI App Development Services
AI App Development Services  ChatGPT integration services
ChatGPT integration services  AI Integration Services
AI Integration Services  Generative AI Development Services
Generative AI Development Services  Natural Language Processing Company
Natural Language Processing Company Machine Learning Development
Machine Learning Development  Machine learning consulting services
Machine learning consulting services  Blockchain Development
Blockchain Development  Blockchain Software Development
Blockchain Software Development  Smart Contract Development Company
Smart Contract Development Company  NFT Marketplace Development Services
NFT Marketplace Development Services  Asset Tokenization Company
Asset Tokenization Company DeFi Wallet Development Company
DeFi Wallet Development Company Mobile App Development
Mobile App Development  IOS App Development
IOS App Development  Android App Development
Android App Development  Cross-Platform App Development
Cross-Platform App Development  Augmented Reality (AR) App Development
Augmented Reality (AR) App Development  Virtual Reality (VR) App Development
Virtual Reality (VR) App Development  Web App Development
Web App Development  SaaS App Development
SaaS App Development Flutter
Flutter  React Native
React Native  Swift (IOS)
Swift (IOS)  Kotlin (Android)
Kotlin (Android)  Mean Stack Development
Mean Stack Development  AngularJS Development
AngularJS Development  MongoDB Development
MongoDB Development  Nodejs Development
Nodejs Development  Database Development
Database Development Ruby on Rails Development
Ruby on Rails Development Expressjs Development
Expressjs Development  Full Stack Development
Full Stack Development  Web Development Services
Web Development Services  Laravel Development
Laravel Development  LAMP Development
LAMP Development  Custom PHP Development
Custom PHP Development  .Net Development
.Net Development  User Experience Design Services
User Experience Design Services  User Interface Design Services
User Interface Design Services  Automated Testing
Automated Testing  Manual Testing
Manual Testing  Digital Marketing Services
Digital Marketing Services 
 Ride-Sharing And Taxi Services
Ride-Sharing And Taxi Services Food Delivery Services
Food Delivery Services Grocery Delivery Services
Grocery Delivery Services Transportation And Logistics
Transportation And Logistics Car Wash App
Car Wash App Home Services App
Home Services App ERP Development Services
ERP Development Services CMS Development Services
CMS Development Services LMS Development
LMS Development CRM Development
CRM Development DevOps Development Services
DevOps Development Services AI Business Solutions
AI Business Solutions AI Cloud Solutions
AI Cloud Solutions AI Chatbot Development
AI Chatbot Development API Development
API Development Blockchain Product Development
Blockchain Product Development Cryptocurrency Wallet Development
Cryptocurrency Wallet Development About Talentelgia
About Talentelgia  Our Team
Our Team  Our Culture
Our Culture 
 Healthcare App Development Services
Healthcare App Development Services Real Estate Web Development Services
Real Estate Web Development Services E-Commerce App Development Services
E-Commerce App Development Services E-Commerce Web Development Services
E-Commerce Web Development Services Blockchain E-commerce
Development Company
Blockchain E-commerce
Development Company Fintech App Development Services
Fintech App Development Services Finance Web Development
Finance Web Development Blockchain Fintech
Development Company
Blockchain Fintech
Development Company E-Learning App Development Services
E-Learning App Development Services Restaurant App Development Company
Restaurant App Development Company Mobile Game Development Company
Mobile Game Development Company Travel App Development Company
Travel App Development Company Automotive Web Design
Automotive Web Design AI Traffic Management System
AI Traffic Management System AI Inventory Management Software
AI Inventory Management Software AI Software Development
AI Software Development AI Development Company
AI Development Company ChatGPT integration services
ChatGPT integration services AI Integration Services
AI Integration Services Machine Learning Development
Machine Learning Development Machine learning consulting services
Machine learning consulting services Blockchain Development
Blockchain Development Blockchain Software Development
Blockchain Software Development Smart contract development company
Smart contract development company NFT marketplace development services
NFT marketplace development services IOS App Development
IOS App Development Android App Development
Android App Development Cross-Platform App Development
Cross-Platform App Development Augmented Reality (AR) App
Development
Augmented Reality (AR) App
Development Virtual Reality (VR) App Development
Virtual Reality (VR) App Development Web App Development
Web App Development Flutter
Flutter React
Native
React
Native Swift
(IOS)
Swift
(IOS) Kotlin (Android)
Kotlin (Android) MEAN Stack Development
MEAN Stack Development AngularJS Development
AngularJS Development MongoDB Development
MongoDB Development Nodejs Development
Nodejs Development Database development services
Database development services Ruby on Rails Development services
Ruby on Rails Development services Expressjs Development
Expressjs Development Full Stack Development
Full Stack Development Web Development Services
Web Development Services Laravel Development
Laravel Development LAMP
Development
LAMP
Development Custom PHP Development
Custom PHP Development User Experience Design Services
User Experience Design Services User Interface Design Services
User Interface Design Services Automated Testing
Automated Testing Manual
Testing
Manual
Testing About Talentelgia
About Talentelgia Our Team
Our Team Our Culture
Our Culture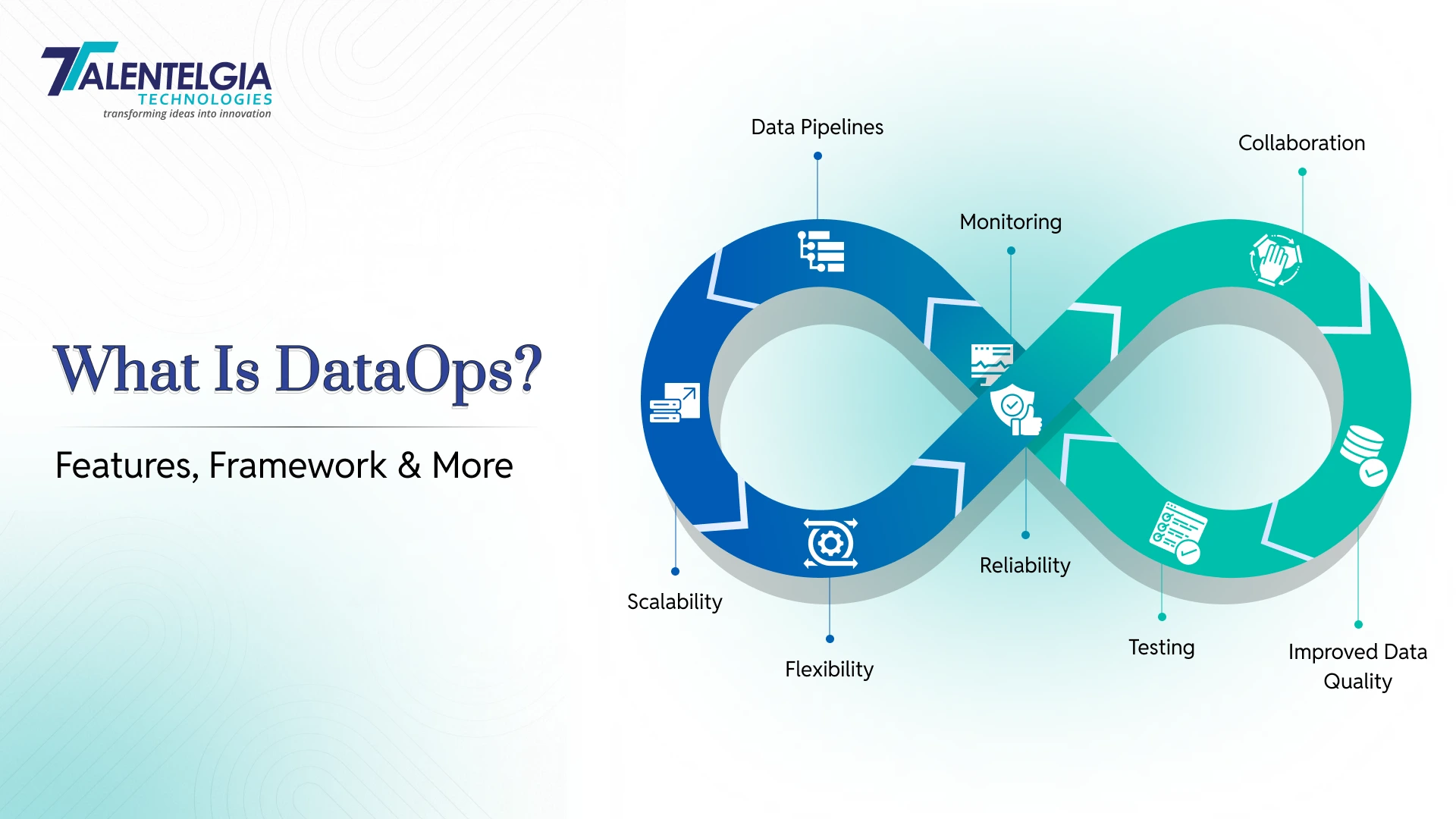
With the advancement of digital businesses, companies are gathering as much data as they can. But transforming that raw data into something valuable, accurate, and speedy enough to make decisions by is the real challenge. Teams are usually plagued by isolated processes, delayed insights, and the relentless demand for timely, valid data. And that’s exactly where DataOps comes into play; it transforms how data teams operate, work together, and provide value. Optimizing the end-to-end data lifecycle enables organizations to do more than just manage data but actually achieve its potential.
This blog post is going to cover what DataOps is, its features, the framework, and why it’s becoming a game-changer for modern businesses. From shattering silos to facilitating decisions that are more intelligent and executed more quickly, you will discover how this path explicitly paves the way to turning mounds of data into great business value.
What Is DataOps?
DataOps is a new approach to data management that enables speed, collaboration, and consistency in how organizations handle data. It is inspired by the principles of DevOps, transforming how the world’s largest organizations deliver value from data. Many businesses even partner with a DevOps Development Company to bring the same automation and agility benefits of DevOps into their DataOps practices. By replacing slow, manual processes with automation, it enables the modeling, deployment, management, and governance of data, all while protecting it. Rather than working behind siloed teams and time-consuming manual processes, DataOps focuses on automation, agility, and ongoing observation to make data move more smoothly across systems: “Data in motion flows under the bridge.”
Through automation of monotonous tasks like data transfer, quality check, and error handling, DataOps enables teams to do less fixing and more learning. This not only minimizes human error but also results in more accessible and reliable data that is provided in real time. Automated, self-service pipelines enable organizations to process more data at a faster pace, yet still comply with governance and accuracy requirements. Ongoing testing and monitoring work in concert to keep data pipelines healthy and help the business make decisions with confidence at scale.
DataOps Vs DevOps
DataOps and DevOps are two sides of the same coin, but have very different goals. Both concepts are oriented towards breaking down silos and enhancing collaboration, but if DevOps is fixated on coding and delivering software, DataOps is all about managing and analyzing data.
This is why the concept of DevOps in Software Development, which encourages bringing together development teams and IT operations to make software more rapidly and reliably available by building, testing, and releasing it at speed. As companies grew and technology stacks became more complex, DevOps has become a necessity to break bottlenecks and enable continuous delivery.
Software Observability is key to massive DevOps Adoption. Through ongoing system monitoring, DevOps engineers can identify problems early, minimize downtime, and ensure a seamless user experience. In software, an observable system rests on three key premises:
- Logs – Full event records that chronicle the what and when.
- Metrics – Quantitative evidence that reflects performance and health over time.
- Active Traces – Events with context that can be used as context across dispersed environments.
These pillars together enable DevOps teams to trust their applications, anticipate failures, and keep flying the plane forward. This shows us that DevOps is all about speeding up delivery and improving teamwork, while observability makes sure you can actually see what’s happening inside your systems. The key difference is that DevOps pushes for speed, and observability makes sure that speed stays stable and reliable.
Let’s take a closer look at how they differ,
| Aspect | DataOps | DevOps |
| Definition | A collaborative data management practice that improves the communication, integration, and automation of data flows between data engineers, scientists, and business teams. | A software development practice that integrates development (Dev) and operations (Ops) to enable continuous integration (CI) and continuous delivery (CD) of applications. |
| Focus | Ensuring reliable, high-quality, and fast delivery of data pipelines, analytics, and AI/ML workflows. | Ensuring reliable, high-quality, and fast delivery of software applications and infrastructure. |
| Primary Stakeholders | Data engineers, data scientists, analysts, and business users. | Developers, IT operations, QA/test engineers. |
| Core Goal | Deliver trusted, clean, and ready-to-use data for decision-making and analytics. | Deliver stable, efficient, and secure software at scale. |
| Key Practices | Data pipeline automation, data testing, monitoring, data quality checks, and metadata management. | Continuous integration, continuous deployment, automated testing, infrastructure as code, and monitoring. |
| Tools | Apache Airflow, dbt, Talend, Great Expectations, Kafka, Snowflake. | Jenkins, Docker, Kubernetes, Ansible, GitLab CI/CD. |
| Challenges Addressed | Data silos, inconsistent data quality, slow analytics delivery, lack of collaboration between data and business teams. | Development-operations silos, slow release cycles, configuration drift, and lack of automation. |
| End Output | Reliable data products (dashboards, ML models, analytics). | Reliable software products (applications, services, APIs). |
Top 5 Features of DataOps
DataOps is quickly becoming the foundation of today’s data-centric enterprises. The point isn’t just to manage data, of course, but to make the whole process faster, smarter, and more reliable. Integrated with automation, collaboration, and governance features, DataOps performs a good job in allowing businesses to exploit the most value out of their data and minimize waste.
In no particular order, here are the 5 key attributes of DataOps, with examples for each:
1. Automation of Data Pipelines
DataOps is built on automation. Instead of manually transferring data from one place to another and checking for errors, under the methodology DataOps, everything is meant to be done through fully automated pipelines that move data, clean it, and make it available for analysis.
Example: A retail store automates the sales data pipeline from point-of-sale (POS) systems to its cloud warehouse. That way, daily reports are ready for business people when they arrive without a person having to do anything.
2. Continuous Testing & Monitoring
Testing is spun throughout the entire data lifecycle in the DataOps worldview. All pipelines are regularly checked for correctness, consistency, and policy.
Example: In finance, banks leverage DataOps to evaluate the quality of data while processing loans. When an error is encountered in the customer credit data, the system automatically limits it before making a decision.
3. Collaboration Across Teams
DataOps eliminates the silos between data engineers, analysts, and even business users, because its structure encourages this level of collaboration via common tools, methodology, and agile practices.
Example: let’s talk about any healthcare app (or education, or finance), DataOps enables IT, physicians, and analysts to work together simultaneously. As patient records are updated, all stakeholders have immediate access to the same data and can work from the best possible information to achieve better health outcomes.
4. Scalability & Flexibility
DataOps pipelines are made to accommodate expanding volume and can quickly accommodate new sources or formats. This is to make sure that businesses remain nimble with their ever-increasing data requirements.
Example: If any video streaming service adopts DataOps to supercharge real-time analytics against millions of daily viewers, then new content information is easily and quickly applied to dashboards without the need to sweep the system.
5. Improved Data Quality & Governance
DataOps applies rules, validation, and governance to ensure data is reliable, accurate, and secure. Better data results in better insights.
Example: An e-commerce company utilizes DataOps to automatically monitor for things like duplicate listings of products or incorrect prices to maintain a smoothly running customer experience and accurate business reports.
Key Elements of DataOps Frameworks
The foundation of the DataOps operating model comprises three key elements: agile methodology, dev(ops) style practices, and lean manufacturing-style principles. Together, they bring order and flexibility to the development of data pipelines to accelerate insight discovery and to the calling of the resulting pipelines to make insight exploitation straightforward, efficient, and affordable. Let’s break it down:
- Agile Methodology: Speed and Adaptability
Agile values marry the notion of small, repeatable sprints to the world of data. Rather than having to wait for weeks or months to make analytics available, DataOps teams can deliver smaller, faster updates that are instantly in sync with business requirements.
Example: A retail business that runs weekly campaigns can rapidly update its data dashboards after every sprint to monitor sales, customer behavior, and ROI in real time.
- DevOps: Automation and Collaboration
DevOps is focused on continuous integration and delivery (CI/CD). When it comes to DataOps, that translates into automating data workflows—from ingesting the data to cleaning and testing it as well as deploying it—while promoting cooperation among IT, data engineers, and data analysts.
Example: An AI Software Development Company can use automation to push new models for fraud detection into production, lessening the need for manual intervention and the time it takes to respond.
- Lean Manufacturing and the concept of efficiency and waste.
Adapted from manufacturing, Lean principles in DataOps are designed to work as efficiently as possible and reduce inefficiency. Rather than wasting time correcting broken pipelines or redoing work, teams optimize their process to keep data flowing smoothly and dependably.
Example: Companies that engage in e-commerce might deploy monitoring software to identify broken data pipelines on the fly; this type of system would save many hours in manual troubleshooting and remove delays in analyzing customer data.
Also Read: Role of AI in DevOps
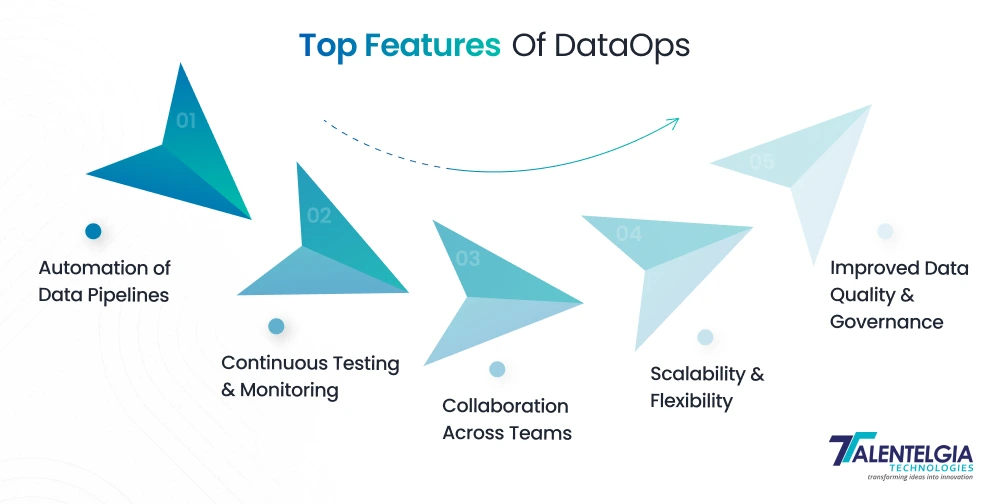
How Does DataOps Work?
The DataOps lifecycle is not just a process, but a repeating cycle that allows the organization to make raw data into trustworthy, business-ready insights. Instead of designing in silos, it unifies teams, tools, and workflows in a way that’s both organised and loose.
Below is an easy-to-understand blueprint of the different lifecycle stages and how each of them adds value:
1. Planning the Foundation
A successful story of any DataOps begins with great planning. This phase is all about aligning business objectives to data requirements. Teams determine the problems they are solving, what data they need, and how to measure success.
- What happens here?
Making sure to identify stakeholders’ needs, to map pipelines, and to set benchmarks.
- Why does it matter?
It helps keep data efforts in line with actual business results.
2. Building and Developing Pipelines
The strategy is developed, and with that, now it’s time for execution. Here, data engineers and analysts develop, code, and iterate on pipelines to process data and model datasets.
- What happens here?
Workflows, version control, and pipeline scalability.
- Why does it matter?
A robust systems development process prevents rework and leads to reusable, efficient data processes.
3. Testing for Quality and Accuracy
No pipeline should proceed without testing. At this step, automated checks are used to verify the quality of data, uncover anomalies, and ensure that the system can perform in the face of diverse conditions.
- What happens here?
Validate, detect anomalies, and stress test your data.
- Why does it matter?
It prevents business decisions from being made on inaccurate or incomplete information.
4. Releasing into Production
This is the place where workflows that have been tested go live. Pipelines are put into production by teams so that data is accessible to decision makers with complete reliability, with no latency.
- What happens here?
Scheduling deploys, watching the rollout, and fixing things that go wrong fast. - Why does it matter?
Quick releases equal fast insights without any business interruption
5. Operating with Reliability
After they are released, pipelines move into operational use. Emphasis is on stability, economy, and resource use.
- What happens here?
Performance monitoring, troubleshooting, and resource control. - Why does it matter?
Operational stability also guarantees that trusted data can be accessed whenever it is needed.
6. Monitoring and Continuous Improvement
And the last phase is not quite an end — it goes back to planning. Ongoing monitoring ensures performance is being tracked, gaps are being identified, and insights are being captured to support better improvements over time.
- What happens here?
Managing KPIs, addressing recurring mistakes, and incorporating feedback.. - Why does it matter?
It makes sure DataOps is flexible, so as processes change, the way you’re doing business is reflected in the processes.
Conclusion
DataOps is more than just a method; it’s a change in mindset around how businesses interact with data. We’ve explored the differences between DevOps and DataOps in this blog, the capabilities that make it strong, and the structure that holds it up. Fundamentally, in comparison to the siloed, stationary past, it allows organizations to break free from barriers and optimally capitalize on all available data assets. For organizations that seek to remain competitive in today’s digital world, implementing DataOps is simply not an option anymore. It makes certain that your data isn’t only collected, but compiled and turned into reliable insights that inform smarter decisions. With automation, collaboration, and governance, DataOps promotes scalability and enables innovation at scale. In other words, adopting DataOps is adopting the future—where data does the business’s bidding faster, cleaner, and more efficiently than ever.















 Write us on:
Write us on:  Business queries:
Business queries:  HR:
HR: