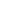Healthcare App Development Services
Healthcare App Development Services
 Real Estate Web Development Services
Real Estate Web Development Services
 E-Commerce App Development Services
E-Commerce App Development Services E-Commerce Web Development Services
E-Commerce Web Development Services Blockchain E-commerce Development Company
Blockchain E-commerce Development Company
 Fintech App Development Services
Fintech App Development Services Fintech Web Development
Fintech Web Development Blockchain Fintech Development Company
Blockchain Fintech Development Company
 E-Learning App Development Services
E-Learning App Development Services
 Restaurant App Development Company
Restaurant App Development Company
 Mobile Game Development Company
Mobile Game Development Company
 Travel App Development Company
Travel App Development Company
 Automotive Web Design
Automotive Web Design
 AI Traffic Management System
AI Traffic Management System
 AI Inventory Management Software
AI Inventory Management Software
 AI Development Company
AI Development Company  ChatGPT integration services
ChatGPT integration services  AI Integration Services
AI Integration Services  Generative AI Development Services
Generative AI Development Services  Natural Language Processing Company
Natural Language Processing Company Machine Learning Development
Machine Learning Development  Machine learning consulting services
Machine learning consulting services  Blockchain Development
Blockchain Development  Blockchain Software Development
Blockchain Software Development  Smart Contract Development Company
Smart Contract Development Company  NFT Marketplace Development Services
NFT Marketplace Development Services  Asset Tokenization Company
Asset Tokenization Company DeFi Wallet Development Company
DeFi Wallet Development Company Mobile App Development
Mobile App Development  IOS App Development
IOS App Development  Android App Development
Android App Development  Cross-Platform App Development
Cross-Platform App Development  Augmented Reality (AR) App Development
Augmented Reality (AR) App Development  Virtual Reality (VR) App Development
Virtual Reality (VR) App Development  Web App Development
Web App Development  SaaS App Development
SaaS App Development Flutter
Flutter  React Native
React Native  Swift (IOS)
Swift (IOS)  Kotlin (Android)
Kotlin (Android)  Mean Stack Development
Mean Stack Development  AngularJS Development
AngularJS Development  MongoDB Development
MongoDB Development  Nodejs Development
Nodejs Development  Database Development
Database Development Ruby on Rails Development
Ruby on Rails Development Expressjs Development
Expressjs Development  Full Stack Development
Full Stack Development  Web Development Services
Web Development Services  Laravel Development
Laravel Development  LAMP Development
LAMP Development  Custom PHP Development
Custom PHP Development  .Net Development
.Net Development  User Experience Design Services
User Experience Design Services  User Interface Design Services
User Interface Design Services  Automated Testing
Automated Testing  Manual Testing
Manual Testing  Digital Marketing Services
Digital Marketing Services 
 Ride-Sharing And Taxi Services
Ride-Sharing And Taxi Services Food Delivery Services
Food Delivery Services Grocery Delivery Services
Grocery Delivery Services Transportation And Logistics
Transportation And Logistics Car Wash App
Car Wash App Home Services App
Home Services App ERP Development Services
ERP Development Services CMS Development Services
CMS Development Services LMS Development
LMS Development CRM Development
CRM Development DevOps Development Services
DevOps Development Services AI Business Solutions
AI Business Solutions AI Cloud Solutions
AI Cloud Solutions AI Chatbot Development
AI Chatbot Development API Development
API Development Blockchain Product Development
Blockchain Product Development Cryptocurrency Wallet Development
Cryptocurrency Wallet Development About Talentelgia
About Talentelgia  Our Team
Our Team  Our Culture
Our Culture 
 Healthcare App Development Services
Healthcare App Development Services Real Estate Web Development Services
Real Estate Web Development Services E-Commerce App Development Services
E-Commerce App Development Services E-Commerce Web Development Services
E-Commerce Web Development Services Blockchain E-commerce
Development Company
Blockchain E-commerce
Development Company Fintech App Development Services
Fintech App Development Services Finance Web Development
Finance Web Development Blockchain Fintech
Development Company
Blockchain Fintech
Development Company E-Learning App Development Services
E-Learning App Development Services Restaurant App Development Company
Restaurant App Development Company Mobile Game Development Company
Mobile Game Development Company Travel App Development Company
Travel App Development Company Automotive Web Design
Automotive Web Design AI Traffic Management System
AI Traffic Management System AI Inventory Management Software
AI Inventory Management Software AI Development Company
AI Development Company ChatGPT integration services
ChatGPT integration services AI Integration Services
AI Integration Services Machine Learning Development
Machine Learning Development Machine learning consulting services
Machine learning consulting services Blockchain Development
Blockchain Development Blockchain Software Development
Blockchain Software Development Smart contract development company
Smart contract development company NFT marketplace development services
NFT marketplace development services IOS App Development
IOS App Development Android App Development
Android App Development Cross-Platform App Development
Cross-Platform App Development Augmented Reality (AR) App
Development
Augmented Reality (AR) App
Development Virtual Reality (VR) App Development
Virtual Reality (VR) App Development Web App Development
Web App Development Flutter
Flutter React
Native
React
Native Swift
(IOS)
Swift
(IOS) Kotlin (Android)
Kotlin (Android) MEAN Stack Development
MEAN Stack Development AngularJS Development
AngularJS Development MongoDB Development
MongoDB Development Nodejs Development
Nodejs Development Database development services
Database development services Ruby on Rails Development services
Ruby on Rails Development services Expressjs Development
Expressjs Development Full Stack Development
Full Stack Development Web Development Services
Web Development Services Laravel Development
Laravel Development LAMP
Development
LAMP
Development Custom PHP Development
Custom PHP Development User Experience Design Services
User Experience Design Services User Interface Design Services
User Interface Design Services Automated Testing
Automated Testing Manual
Testing
Manual
Testing About Talentelgia
About Talentelgia Our Team
Our Team Our Culture
Our Culture
Artificial Intelligence (AI) has transitioned from research laboratories to the very center of daily business and technology. From suggesting what you might watch next on Netflix to fraud detection in banking systems, AI is revolutionizing decision-making and experience delivery. But behind each intelligent algorithm lies a well-designed AI model architecture—the structural organization that dictates how data moves, how models are trained, and how smart results are generated.
According to McKinsey, 78% of the participants indicated that their companies now utilize AI in a minimum of one business function, a dramatic increase from 72% in early 2024 to only 55% in the previous year. This sudden spike indicates not just increasing adoption but also increasing dependence on scalable, effective AI architectures to facilitate innovation and decision-making.
In this blog, we will demystify what AI model architecture is, discuss its main types, guide you through the 7-layer AI model architecture, and touch on upcoming architectural trends that are defining the future of machine learning. Let’s get started:
What Is AI Model Architecture?
AI model architecture is the underlying structure that determines how an artificial intelligence system processes information, learns from it, and produces accurate output. Just as an architect designs the floor plan of a building—choosing how rooms are connected, what materials to employ, and how the building stands—researchers create model architectures to establish how information is passed along, how it makes decisions, and how it produces results.
Simply put, AI model architecture is the system structure of an AI system that dictates the way it interprets inputs, performs processes, and generates results.
There are three main categories of AI models according to architectural design:
Rule-Based Systems
These are the first AI models constructed on static, pre-defined rules. For instance, a chatbot designed to reply with “Hi there!” whenever it is given “Hello” is employing a rule-based system. Although simple to implement, they are inflexible and cannot adjust to new or unexpected inputs.
Machine Learning Models
Machine Learning models learn from data rather than just rules. They recognize patterns, make predictions, and get better with exposure to more data. An everyday example is a spam filter that learns to recognize junk mail based on past data and user habits.
Deep Learning Models
An influential branch of machine learning, deep learning employs multi-layered neural networks that replicate how the human brain learns. Such architecture supports sophisticated features such as facial recognition, natural language processing, autonomous driving technology, and many others.
Quick Read: How To Build An AI Model?
Types Of AI Model Architectures
AI model architectures serve as the foundational frameworks that shape how artificial intelligence systems interpret data, identify patterns, and deliver outcomes. From recognizing images to generating human-like text or understanding sequences, each architecture is used for a particular purpose and performs particularly well in specific areas. A detailed overview of the most commonly used AI model architectures and their applications in real-world scenarios follows:
1. Feedforward Neural Network (FNN)
Feedforward Neural Network (FNN) is an artificial neural network (ANN) where information flow is unidirectional—only from the input layer, one or several hidden layers, to the output layer. Such a simple setup forms the essence of most machine learning models and is applied greatly in pattern recognition, classification, and regression-type tasks.
Use Cases of Feedforward Neural Network (FNN):
- Diagnostics in healthcare: Merging neural image models with medical ontologies for reliable and interpretable disease diagnosis.
- Legal AI: Facilitating compliance checks and contract review by translating natural language into formal logic.
- Scientific discovery: Helping molecular structure prediction with graph neural networks and chemical rules.
- Robotics & planning: Augmenting autonomous agents with rule-compliance logic for path planning or action execution.
- Explainable AI (XAI): Creating models for high-risk situations in which all choices will have to be explained.
2. Convolutional Neural Network
A Convolutional Neural Network (CNN) is a robust deep learning architecture engineered to process image-based tasks, including object recognition, image classification, and scene understanding. What differentiates CNNs from conventional neural networks is the capacity to perceive spatial hierarchies in data with layers especially developed for visual processing. At the core of this design is the convolutional layer — the quintessential building block tasked with identifying meaningful patterns in visual inputs.
Use Cases of CNNs with Convolutional Layers:
- Autonomous vehicles utilize CNNs to identify road signs, pedestrians, and lanes.
- Medical imaging employs CNNs to identify tumors and diagnose.
- Facial recognition technologies depend on convolutional layers to identify distinct facial features.
- Security systems, robotics, and even video games utilize CNNs to process visual inputs in real-time
3. Recurrent Neural Networks (RNNs)
RNNs are neural networks specifically created to process sequential data by having a “memory” of past inputs using internal loops. It differs from standard feedforward networks in that it transmits information from one time step to the next, allowing it to capture temporal dependencies. It have vanishing gradients, which prevent them from learning long-term dependencies easily. LSTMs (Long Short-Term Memory) and GRUs (Gated Recurrent Units) are variations created to overcome these limitations.
Use Cases of Recurrent Neural Networks (RNNs):
- Language modeling and text generation
- Speech recognition
- Time-series forecasting (e.g., stock prices, weather)
- Machine translation
- Music composition and sequence generation
4. Generative Adversarial Networks (GANs)
A Generative Adversarial Network (GAN) is a form of deep learning computer model that employs an ingenious two-component system to generate new, realistic information from patterns learned in raw datasets. Imagine it as a computer artist learning to copy reality: one component of the model (the generator) generates new content, while the other component (the discriminator) assesses whether the content appears real or artificial. Gradually, the generator becomes more skilled at deceiving the discriminator, and the result becomes more and more realistic.
GANs are particularly useful for applications such as creating new images, music, or even words—any field in which learning from current data to produce original work is useful. The adversarial configuration—two models competing against each other and refining themselves via feedback—assists GANs in reaching extremely high-quality outcomes.
Use Cases of Generative Adversarial Networks (GANs):
A. Image Generation and Editing
GANs are commonly applied to create hyper-realistic images from scratch or to refine and alter existing images. Uses include:
- Developing realistic avatars and faces
- Improving image quality (e.g., upscaling low-resolution images)
- Converting black-and-white photographs to color
- Creating art or concept images from basic sketches or text inputs
This technology is a key contributor to industries such as gaming, film, fashion, and digital content creation.
B. Machine Learning Synthetic Data Generation
High-quality training data is critical to developing trustworthy machine learning models, but actual data can be limited or sensitive. GANs provide an intelligent solution by generating synthetic datasets that reflect real-world patterns.
For instance:
- Simulating financial fraud cases to enhance fraud detection systems
- Creating varied medical records for training healthcare AI models without compromising patient privacy
This method assists in enhancing model performance and minimizing data collection issues.
C. Gap Filling for Incomplete Data
When data sets have gaps, GANs can fill the blanks intelligently by understanding correlations in the available data. This can prove to be particularly helpful in:
- Environmental and geological modeling (predicting subsurface structures from surface data)
- Repairing distorted images or video
- Reconstructing missing areas of scanned documents or paintings
In fields such as energy, oil exploration, and carbon storage, this feature can save resources and time.
5. Transformers
Transformers are a revolutionary neural network model created to work with sequential information—text, audio, or even visual information. Unlike classical models that break down data in a step-by-step manner, transformers are capable of processing sequences in their entirety at once. This is accomplished through a key component called self-attention that enables the model to grasp how different elements in the sequence interact with each other regardless of the distance between them.
First developed for natural language processing (NLP), transformers are fast becoming the model of choice for virtually any type of AI task because they can capture deep contextual understanding as well as long-range relationships. Whether translating languages, creating human-like text, or extracting image patterns, transformers are providing state-of-the-art results across the board.
Real-Life Use Cases of Transformers:
Transformer models have transformed how machines deal with sequential data—anything that unfolds in a particular order, such as language, code, music, or genetic code. With their capacity to read complex patterns and long-distance relationships, transformers are driving some of the most powerful applications in AI right now. Here are some of the most significant real-world applications:
A. Natural Language Processing (NLP)
Transformers are the backbone of modern language understanding, making it possible for machines to read, interpret, and generate human language with high accuracy and fluency. They are applied in the following:
- Text summarization: Reducing long documents into shorter, meaningful summaries.
- Content generation: Contextual response, article, or dialogue generation.
- Voice assistants: AI like Alexa and Siri use transformer-based models to decipher user intention and provide context-specific responses.
- Sentiment analysis: Reading the tone or feeling behind customer feedback, social media, or user reviews.
B. Real-Time Machine Translation
Models based on the Transformer have significantly enhanced language translation quality, which has become smoother and contextually more accurate.
Google Translate and DeepL, among other tools, now employ transformers to handle sentences as a whole, thus keeping grammar, idioms, and subtleties intact.
This facilitates smooth communication between languages for business, travel, learning, and diplomacy.
C. Genomic and DNA Sequence Analysis
Transformers are breaking new ground in gene studies in the field of bioinformatics. When DNA sequences are handled as natural language, transformers can:
- Identify patterns in gene information.
- Anticipate the effects of mutations.
- Pinpoint DNA areas connected with diseases or hereditary characteristics.
This is very important in precision medicine, where treatment is individualized according to one’s gene makeup.
D. Protein Structure Prediction
Knowing how proteins fold into three-dimensional structures is crucial for disease research and drug discovery. Transformer models, including those employed by AlphaFold, have made gigantic leaps in this area.
Such models examine sequences of amino acids and forecast the intricate 3D structures they adopt.
This speeds up the identification of new treatments and allows scientists to learn about biological processes at a molecular level.
E. Programming and Code Generation
Transformers are also revolutionizing the world of software development. Training on huge stores of source code, these models can:
- Autocomplete code snippets.
- Translate code from one programming language to another.
- Spot bugs or propose changes.
GitHub Copilot and ChatGPT for coding are tangible instances of transformer-based developer aides.
6. Autoencoders
An autoencoder is a deep neural network specifically formed to learn effective representations of data by compressing input into its most critical features and then reconstructing the original input from this compressed form. It has two components: an encoder, which compresses the dimensionality of the input data, and a decoder, which tries to reconstruct the original data from this compressed version. This architecture allows the model to learn only the most important patterns in the data while eliminating noise or unnecessary details.
Autoencoders are trained on unsupervised learning, or they do not need labeled data. While being trained, the model discovers how to detect hidden patterns, or latent variables, which determine the input structure. These variables constitute a latent space, a dense and abstract representation that has only the essential information to recreate the input. Through learning to reconstruct data from this latent space, autoencoders become very useful for applications such as data compression, image denoising, and anomaly detection.
Use Cases of Autoencoders:
1. Effective Compression of Images and Audio
Autoencoders also compress big files of images and audio without destroying the vital information. They know how to put the data in a compact state and then unravel it back into its original structure. This also makes them most suitable for smaller file sizes in preserving the original quality, making to utilize in storage as well as transit.
2. Intelligent Anomaly Detection
Want to catch outliers in your data? Autoencoders help. Train them on “normal” data sets only. When something rare turns up, the autoencoder cannot reconstruct it well, indicating it as an anomaly. This works wonderfully in fraud detection, cybersecurity, and fault monitoring.
3. Dimensionality Reduction and Simplifying Complex Data
High-dimensional data can be overwhelming. Autoencoders assist by discovering a compressed representation of the data that retains all the significant patterns. This lower-dimensional form can accelerate additional analysis and visualization without sacrificing fundamental insights.
4. Generating New, Realistic Data
Autoencoders can also function as data generators. By taking a sample from their compressed (latent) space and passing it through the decoder, they are able to create new data that is very similar to the original training data. This is particularly beneficial for domains such as creative design, medical imaging, and synthetic data generation for machine learning algorithms.
7 Layers Of AI Model Architecture
Deploying AI effectively at the enterprise level takes more than strong models—it takes a solid, layered architecture aligned to technical and business objectives. The following is a description of the 7 AI layers that are the foundation of scalable, production-grade artificial intelligence systems:
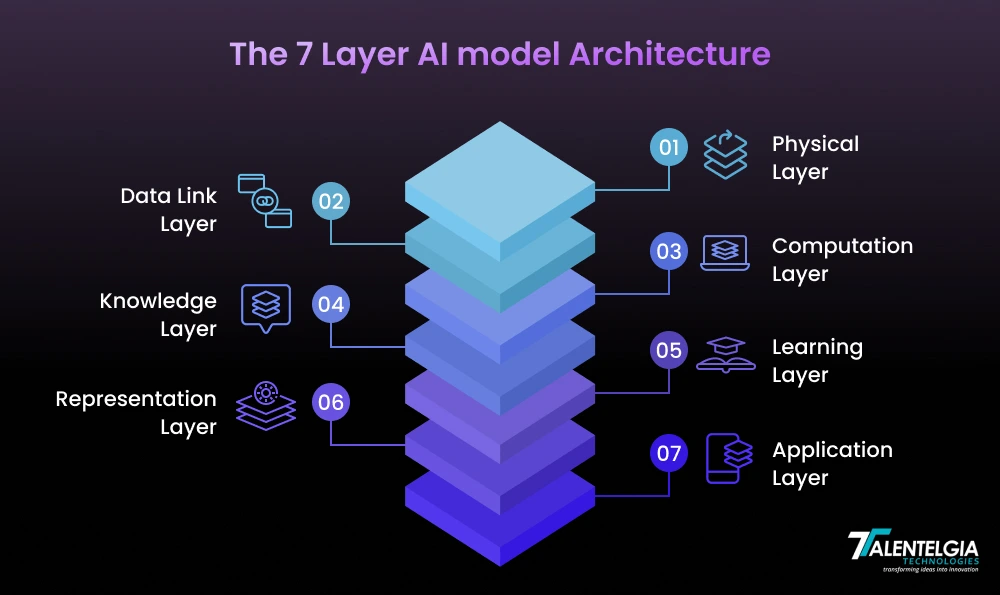
1. Physical Layer: The Infrastructure That Powers AI
This bottom layer encompasses every piece of hardware and compute infrastructure, like GPUs, TPUs, edge nodes, and cloud. It’s where AI lives, literally. Enterprises need to balance cost, performance, and scalability carefully when constructing this bottom layer. It’s like the concrete foundation of your AI ecosystem—stable enough to handle expansion and growth.
2. Data Link Layer: Constructing Reliable Data Pipelines
The Data Link Layer provides clean, governed, and integrated data pipelines. It manages everything from real-time data ingestion and API management to data quality checks and governance rules. For big companies, this layer normalizes how data moves across systems, establishing a trusted base for training and deploying AI models.
3. Computation Layer
This is AI’s engine room. Whether it’s deep learning models, legacy machine learning algorithms, or analytics workloads, this layer gives you the compute environments—either containers, serverless platforms, or GPU clusters. Scalable orchestration frameworks like Kubernetes make it easier for teams to manage resource-intensive processes.
4. Knowledge Layer: Translating Data into Organizational Intelligence
AI is not prediction—it’s comprehension. The Knowledge Layer adds semantic databases, knowledge graphs, and NLP engines to pull out insights and document business knowledge. This enables organizations to make informed decisions while making key information reusable across departments.
5. Learning Layer: Model Training & Continuous Optimization
This is where AI models get trained, optimized, and refined over time. Right from hyperparameter tuning to auto-retraining loops, this layer deeply connects with CI/CD pipelines, AIOps, and DevOps tools to make models agile and current. Enterprises need to make these workflows reliable and reproducible.
6. Representation Layer: Versioning and Storing Model Metadata
When your models have been trained, they must be packaged, versioned, and stored securely. The Representation Layer does this by making models auditable, reproducible, and tracked. MLOps makes this happen—essential for data science team scaling, compliance, and collaboration.
7. Application Layer: Deploying AI to Real-World Applications
At the pinnacle is the Application Layer, where business meets AI. From predictive analytics dashboards to chatbots and automation tools based on AI, this layer concentrates on integrating AI into business workflows. User Experience, security, and alignment with business objectives are top priorities here.
Latest Trends In AI Model Architecture
Artificial Intelligence is changing not only in what it can do, but how it’s constructed. With increasing demands for performance, efficiency, and human-like comprehension, new model architectures are expanding the limits of what’s achievable. From huge expert systems to human-inspired multimodal networks, today’s models are smarter, leaner, and more flexible than ever.
Let’s dive into the most important architectural trends defining the future of AI:
1. Mixture Of Experts
Mixture of Experts (MoE) is a complex neural network structure where only a part of the model parameters (experts) is used for each forward pass. In contrast to regular dense models that apply all weights for all inputs, MoE sends different inputs to different “expert” subnetworks, so the model is sparser, quicker, and more scalable.
This architecture allows big models to remain high-performance without needing too much computational power. The most important part is a learned gating mechanism that dynamically determines which experts must process an input, enhancing both training speed and inference.
Why is it popular?
- Allows models with hundreds of billions of parameters to be trained while only using a fraction at a time.
- Reduces compute cost and memory footprint, making it ideal for massive-scale deployments.
- Perfect for scenarios where model size and inference speed need to go hand in hand, such as chatbots, real-time recommendation systems, and so on.
Popular MoE Models (Examples):
- Google Switch Transformer: An early MoE model that scales to trillions of parameters while preserving training efficiency.
- Mistral Mixtral 8×7 B: An open-weight MoE model with 8 expert networks, using only 2 per forward pass.
- GShard by Google: Introduced sharding across devices with MoE routing, setting the stage for scalable training.
2. Multimodal Architecture
Multimodal architectures refer to AI models that can interpret and fuse information from different types of data, including text, images, audio, and video. As opposed to typical models that deal with a single modality (e.g., text in NLP or pixels in vision), multimodal models are capable of analyzing, generating, and reasoning on different input forms at the same time.
These architectures usually employ shared embedding spaces or cross-attention mechanisms to merge inputs from various sources. This blending enables them to perceive context more comprehensively, resulting in richer outputs, such as describing images in natural language, interpreting video clips with audio, or responding to visual stimuli with correct captions.
Why is it trending?
- Human-like perception: Imitates the way humans naturally perceive the world—using vision, hearing, and language simultaneously.
- Improved capabilities: Enables sophisticated applications such as visual question answering (VQA), image captioning, voice assistants, and augmented reality.
- Wider application: Applied across industries ranging from healthcare (e.g., radiology reports) to e-commerce (product search by images and descriptions) and robotics (visual + tactile sensing).
Popular Multimodal Models (Examples):
- OpenAI’s GPT-4 (Multimodal): Can accept both text and image inputs, enabling tasks like image description and visual reasoning.
- Google Gemini (2023–24): Designed for advanced multimodal tasks across video, text, code, and images.
- Meta’s ImageBind: Trains models across six modalities (text, image, audio, depth, thermal, motion), aligning them into a single embedding space.
- Claude 3 by Anthropic: Works with multimodal inputs with excellent reasoning capabilities, especially for image-present documents, charts, or diagrams.
Quick Read: GPT-4 Vs GPT-4 Turbo
3. Open Weight Foundation Models
Open-weight foundation models are pretraining AI models published with publicly available weights for download, enabling developers, researchers, and companies to download, fine-tune, and run them locally. As opposed to proprietary models (such as GPT-4), open-weight models provide transparency, customization, and complete control.
These models are also becoming smaller but wiser. Due to architectural innovations and optimized training methods, even models with 7B or fewer parameters can now do well on difficult NLP and reasoning tasks. They’re optimized for efficiency, cost, and deployment in on-device or low-resource settings.
Why is it trending?
- Democratizes AI development: AI development Companies can leverage the latest models without depending on big tech APIs.
- Personalized & Private: Supports local deployment, fine-tuning on proprietary data, and full control over sensitive workflows.
- Cost-effective: Reduced inference costs and reduced hardware requirements make these models perfect for startups and edge computing.
Popular Open-Weight & Lightweight Foundation Models (Examples):
- Mistral 7B: An open-weight language model that surpasses large models in most benchmarks.
- Gemma by Google: A series of open models with a focus on safety, efficiency, and consumer hardware performance.
- Phi-3 by Microsoft: A lightweight model that can match or surpass much larger models, optimized for reasoning and instruction following.
- LLaMA 3 by Meta: The newest in Meta’s open LLaMA line, providing both performance and scalability for tailored applications.
4. Neural Symbolic Hybrids
Neural-symbolic hybrids are AI systems that combine the pattern-recognition ability of neural networks with the structured reasoning of symbolic logic. Although deep learning excels at perception tasks like image recognition and natural language understanding, symbolic systems are better suited for formal reasoning, rule-following, and interpretability.
By combining the two paradigms, neural-symbolic models attempt to create models that not only excel but are explainable, generalizable, and human-logic compliant. Such models tend to incorporate graph-based reasoning, program synthesis, or explicit logic parts into a neural structure.
Why is it popular?
- Better reasoning: Ideal for step-by-step logic-intensive tasks such as code generation or theorem proving.
- Interpretability: Allows AI choices to become more comprehensible and reliable, especially in security-critical usage like healthcare, finance, and law.
- Generalization: More effective at handling edge cases and applying learned understanding to novel contexts.
Popular Neural-Symbolic Systems (Examples):
- DeepMind’s AlphaCode 2: Combines symbolic reasoning with neural models to tackle competitive programming problems that involve logic and planning.
- Neuro-Symbolic Concept Learner (NS-CL): A visual question answering hybrid model that integrates deep visual perception with symbolic reasoning.
- Graph Neural Networks with Rule-Based Systems: Applied to molecular biology, recommender systems, and detection of fraud to represent structured relationships and logical constraints.
Conclusion
AI model architectures are the underlying building blocks that enable everything from smart assistants to state-of-the-art medical and scientific advancements. From the simplicity of feedforward networks, the visual capability of CNNs, the sequence memory of RNNs, the creative generative ability of GANs, or the contextual dominance of transformers, every architecture has a special role in the ever-growing AI universe. As companies adopt AI at never-before-seen rates, familiarizing oneself with these architectures is crucial to designing smarter, scalable, and future-proof solutions.
















 Write us on:
Write us on:  Business queries:
Business queries:  HR:
HR: