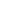Healthcare App Development Services
Healthcare App Development Services
 Real Estate Web Development Services
Real Estate Web Development Services
 E-Commerce App Development Services
E-Commerce App Development Services E-Commerce Web Development Services
E-Commerce Web Development Services Blockchain E-commerce Development Company
Blockchain E-commerce Development Company
 Fintech App Development Services
Fintech App Development Services Fintech Web Development
Fintech Web Development Blockchain Fintech Development Company
Blockchain Fintech Development Company
 E-Learning App Development Services
E-Learning App Development Services
 Restaurant App Development Company
Restaurant App Development Company
 Mobile Game Development Company
Mobile Game Development Company
 Travel App Development Company
Travel App Development Company
 Automotive Web Design
Automotive Web Design
 AI Traffic Management System
AI Traffic Management System
 AI Inventory Management Software
AI Inventory Management Software
 Machine Learning Development
Machine Learning Development ChatGPT integration services
ChatGPT integration services  AI Development Company
AI Development Company  AI Integration Services
AI Integration Services  Generative AI Development Services
Generative AI Development Services  Natural Language Processing Company
Natural Language Processing Company Mobile App Development
Mobile App Development  IOS App Development
IOS App Development  Android App Development
Android App Development  Cross-Platform App Development
Cross-Platform App Development  Augmented Reality (AR) App Development
Augmented Reality (AR) App Development  Virtual Reality (VR) App Development
Virtual Reality (VR) App Development  Web App Development
Web App Development  SaaS App Development
SaaS App Development Flutter
Flutter  React Native
React Native  Swift (IOS)
Swift (IOS)  Kotlin (Android)
Kotlin (Android)  Mean Stack Development
Mean Stack Development  AngularJS Development
AngularJS Development  MongoDB Development
MongoDB Development  Nodejs Development
Nodejs Development  Database Development
Database Development Ruby on Rails Development
Ruby on Rails Development Expressjs Development
Expressjs Development  Full Stack Development
Full Stack Development  Web Development Services
Web Development Services  Laravel Development
Laravel Development  LAMP Development
LAMP Development  Custom PHP Development
Custom PHP Development  .Net Development
.Net Development  User Experience Design Services
User Experience Design Services  User Interface Design Services
User Interface Design Services  Automated Testing
Automated Testing  Manual Testing
Manual Testing  Digital Marketing Services
Digital Marketing Services 
 Ride-Sharing And Taxi Services
Ride-Sharing And Taxi Services Food Delivery Services
Food Delivery Services Grocery Delivery Services
Grocery Delivery Services Transportation And Logistics
Transportation And Logistics Car Wash App
Car Wash App Home Services App
Home Services App ERP Development Services
ERP Development Services CMS Development Services
CMS Development Services LMS Development
LMS Development CRM Development
CRM Development DevOps Development Services
DevOps Development Services AI Business Solutions
AI Business Solutions AI Cloud Solutions
AI Cloud Solutions AI Chatbot Development
AI Chatbot Development API Development
API Development Blockchain Product Development
Blockchain Product Development Cryptocurrency Wallet Development
Cryptocurrency Wallet Development About Talentelgia
About Talentelgia  Our Team
Our Team  Our Culture
Our Culture 
 Healthcare App Development Services
Healthcare App Development Services Real Estate Web Development Services
Real Estate Web Development Services E-Commerce App Development Services
E-Commerce App Development Services E-Commerce Web Development Services
E-Commerce Web Development Services Blockchain E-commerce
Development Company
Blockchain E-commerce
Development Company Fintech App Development Services
Fintech App Development Services Finance Web Development
Finance Web Development Blockchain Fintech
Development Company
Blockchain Fintech
Development Company E-Learning App Development Services
E-Learning App Development Services Restaurant App Development Company
Restaurant App Development Company Mobile Game Development Company
Mobile Game Development Company Travel App Development Company
Travel App Development Company Automotive Web Design
Automotive Web Design AI Traffic Management System
AI Traffic Management System AI Inventory Management Software
AI Inventory Management Software AI Development Company
AI Development Company ChatGPT integration services
ChatGPT integration services AI Integration Services
AI Integration Services Machine Learning Development
Machine Learning Development Machine learning consulting services
Machine learning consulting services Blockchain Development
Blockchain Development Blockchain Software Development
Blockchain Software Development Smart contract development company
Smart contract development company NFT marketplace development services
NFT marketplace development services Asset tokenization companies
Asset tokenization companies DeFi Wallet Development Company
DeFi Wallet Development Company IOS App Development
IOS App Development Android App Development
Android App Development Cross-Platform App Development
Cross-Platform App Development Augmented Reality (AR) App
Development
Augmented Reality (AR) App
Development Virtual Reality (VR) App Development
Virtual Reality (VR) App Development Web App Development
Web App Development Flutter
Flutter React
Native
React
Native Swift
(IOS)
Swift
(IOS) Kotlin (Android)
Kotlin (Android) MEAN Stack Development
MEAN Stack Development AngularJS Development
AngularJS Development MongoDB Development
MongoDB Development Nodejs Development
Nodejs Development Database development services
Database development services Expressjs Development
Expressjs Development Full Stack Development
Full Stack Development Web Development Services
Web Development Services Laravel Development
Laravel Development LAMP
Development
LAMP
Development Custom PHP Development
Custom PHP Development User Experience Design Services
User Experience Design Services User Interface Design Services
User Interface Design Services Automated Testing
Automated Testing Manual
Testing
Manual
Testing About Talentelgia
About Talentelgia Our Team
Our Team Our Culture
Our Culture
One of the greatest hurdles companies face today is bringing a machine learning model from development to production. It’s the models that work well in a lab environment but then falter when exposed to real-world data, changing business requirements, or the limitations of the infrastructure. Filling this gap requires more than simply constructing accurate models; it necessitates a disciplined methodology that integrates data science, engineering, and operations. In this post, we’re going to talk about what MLOps is, the components of MLOps, and how to implement MLops. And the difference between MLops and DevOps. Let’s get started:
What is MLops?
MLOps (or Machine Learning Operations) are a series of practices that aim to simplify the deployment, monitoring, and management of machine learning models in production. It fills the gap between data science and operations teams, making sure that ML models run as expected in production and systems can be continuously improved.
Born from DevOps in Software Development, MLOps focuses on overcoming the operationalized AI and machine learning challenges. Data scientists are responsible for building and training models, and engineers take charge of deploying and maintaining them. MLOps facilitates a collaborative workflow, which allows enterprises to deploy ML models quickly, above and beyond keeping performance in control and tangible value flowing in real applications.
Why Do You Need MLOps?
MLOps isn’t just a technical process; it’s the foundation for scaling AI Business Solutions effectively. By streamlining how machine learning models are developed, deployed, and maintained, MLOps helps businesses unlock new revenue streams, reduce operational costs, and enhance decision-making with data-driven insights. From automating workflows to improving customer experience, MLOps bridges the gap between AI research and real-world enterprise adoption.
Without this framework, achieving consistent results is difficult. Automating model pipelines accelerates time-to-market while keeping expenses under control, allowing teams to stay agile in rapidly changing industries. Whether it’s handling sensitive data, working with limited budgets, or managing small teams, MLOps provides the flexibility to adapt practices to fit your unique business environment.
The real power of MLOps lies in its adaptability; it’s not a one-size-fits-all solution. Companies can experiment, refine, and retain only the practices that align with their strategic goals. By bridging the gap between the role of AI in DevOps and machine learning operations, MLOps becomes more than a process; it evolves into a growth enabler for businesses that want to stay competitive in the AI-driven era.
Benefits Of MLOps
Think of MLOps as the “project manager” for your AI initiatives. Without it, machine learning models risk staying stuck in the lab, full of potential but unable to scale. With it, businesses can bring structure, speed, and strategy to their AI journey. Whether you’re building complex web development projects, launching innovative app development ideas, or integrating cutting-edge AI integration services, MLOps ensures your efforts deliver consistent, measurable results.
1. Faster deployments
By streamlining workflows through automation and continuous testing, MLOps ensures that ML models can move from experimentation to production rapidly. This agility helps companies launch smarter apps, enhance web platforms, and update AI-driven features with faster time-to-market.
2. Improved collaboration.
MLOps bridges the gap between data scientists, developers, and IT teams. Just like in agile web or app development projects, breaking down silos fosters smoother communication and reduces bottlenecks. The result: end-to-end collaboration from data preparation to deployment and monitoring.
3. Higher-quality models.
When supported by an MLOps framework, AI models are not only more accurate but also adaptive to evolving datasets. Businesses that pair MLOps with AI integration services can build more reliable and intelligent products, whether it’s a recommendation system in an app or advanced analytics in a web platform.
4. Enhanced efficiency.
Automation removes repetitive, time-consuming tasks, freeing up experts to focus on high-value problem-solving and innovation. This mirrors the productivity gains seen in web and app development when workflows are optimized, ensuring businesses spend more time creating impact and less time managing manual tasks.
How to Implement MLOps?
MLOps products are important for companies that want to tighten up their machine learning operations and make the most out of AI models. Machine Learning Operations (MLOps), also known as AI/ML Ops, enable teams to bring control and efficiency to the full lifecycle of ML models, from development and deployment to monitoring and management. The MLOps deployment has been split into three groups, based on the level of automation and maturity. Here’s a step-by-step breakdown.
1. MLOps Level 0
MLOps Level 0 is the initial stage of Machine Learning Operations (MLOps) for your organization if you are getting started with AI/ML Ops. There is no automation at this tier in the machine learning pipeline. Every part, including data preparation, model training, testing, or deployment, is manually managed by data scientists.
Key Features:
- Manual Workflow: All the steps (preprocessing, training, and validation) are manually performed by data scientists through scripts and notebooks.
- Decoupling of Responsibilities: Data scientists write models, engineers deploy them (as a prediction service and as an API).
- Rare Refreshment: Models are updated or retrained seldomly.
- No CI/CD – Continuous integration and deployment is not as common.
- Scant Monitoring: Model performance monitoring is scarce, and API deployment may include some security or load testing; prediction monitoring tends to be an afterthought.
Challenges:
Manual machine learning operations MLOps struggle to handle real-world changes in data. Implementing CI/CD and continuous testing improves reliability and performance.
2. MLOps Level 1
Level 1 MLOps consists of automation of the ML pipeline to have continuous model training and real-time prediction serving.
Key Features:
- Automated Experiments: ML experiment is coordinated on automation, and no interference from human parameters.
- No need to retrain models: continuous training with the latest data ensures predictions are current.
- Pipeline Consistency: The consistent pipeline from development through preproduction to production environments helps stable machine learning op use.
- Reusable Components: Pipelines and components can be reused and are Docker containerized for flexibility.
- Online Model Delivery: Models as prediction services are serving immediately after they are trained.
- Automated Pipeline Deployment: Full training pipeline runs periodically and updates models to production easily.
Additional Components:
- Data & Model Validation: Automated checks ensure both incoming data and models meet quality standards.
- Feature Repository: Centralized storage for features used in training and serving ensures consistency.
- Metadata Management: Tracks pipeline executions for reproducibility, debugging, and audit purposes.
- Pipeline Activation: Models retrain automatically based on triggers like new data, scheduled intervals, or performance drops.
Challenges:
Level 1 is fine for dynamic environments, but if you want to play with new ML concepts, a better CI/CD pipeline is needed to test and deploy code quickly.
3. MLOps Level 2
Level 2 MLOps is the most advanced maturity, with fully automated CI/CD pipelines in place to enable fast and frequent model updates and experimentation. This is perfect for AI/ML Ops at a massive scale in production.
Key Features:
- Experimentation & Iterative Development: New ML algorithms, feature engineering, and hyperparameters are creatively tested iteratively under most cases in repositories to track source code changes.
- Pipeline CI: Automated build, test, and package of pipeline artifacts help to ensure deployments are consistent.
- Pipeline CD: released packages are deployed to production automatically in a CI/CD fashion that can crowdsource from the federation any model that meets acceptance.
- Automated triggers: Pipelines retrain and deploy models according to schedule, new data, or model performance deterioration.
- Persistent Model Provision: Trained models are directly available as prediction utilities.
- Monitoring & Feedback: We now monitor in real time, and when necessary, we trigger a new pipeline cycle or experiment.
Challenges:
Level 2 is agile, resource-efficient, and meticulous work. Infrastructure can be strained by frequent retraining, while feature store and metadata management is complicated. Automatic data analysis, model validation, and pipeline triggering are necessary for a stable model.
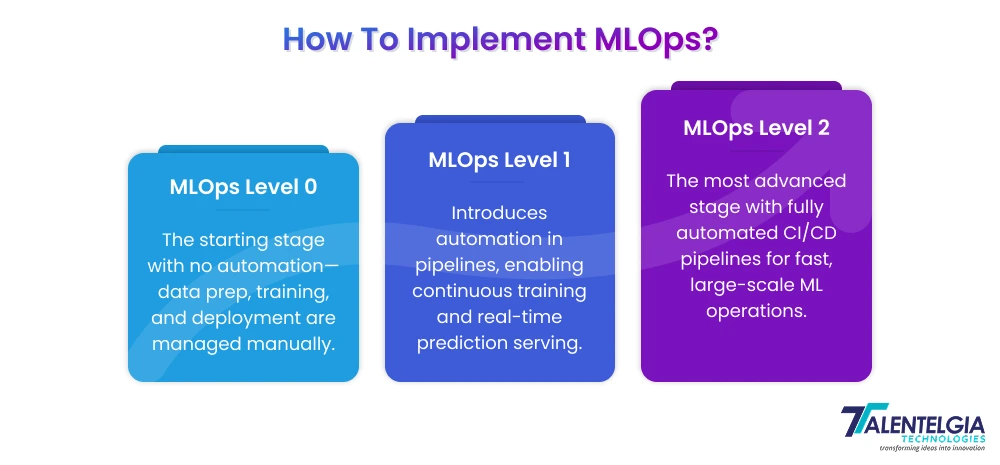
MLops Lifecycle
Implementing machine learning at scale requires more than just building a model—it demands a structured approach that connects data, development, deployment, and ongoing optimization.
The MLOps lifecycle provides this framework, ensuring reliability, scalability, and alignment with business goals. Below are the key stages every organization should follow:
1. Define the Problem
The initial step in the MLOps lifecycle is to define the problem that your ML model requires solving. This includes:
- Establishing clear goals for the project.
- Establishing target KPI’s to measure success.
A clear problem description is key to aligning all subsequent steps with the business context and KPIs.
2. Data Collection and Preparation
High-quality data is the backbone of successful AI/ML Ops. In this stage, teams:
- Collect relevant data from multiple sources.
- Clean, filter, and transform the data to ensure consistency.
- Prepare it for model training by handling missing values, normalizing features, and creating training/testing datasets.
Proper data preparation is crucial, as the accuracy and efficiency of the model directly depend on the data quality.
3. Model Development
After data becomes available, data scientists can work on building machine learning models that involve:
- Selecting the right algorithms.
- Tuning hyperparameters for optimal performance.
- Evaluating the model on scalar metrics (accuracy, precision, recall or F1-score).
This is an iterative Stage, and models are repeatedly improved until they reach acceptable levels of performance.
4. Model Monitoring and Maintenance
Deployment is not the final step. Continuous monitoring ensures your model performs reliably under real-world conditions:
- Track model performance using KPIs and real-time metrics.
- Detect issues like model drift or declining accuracy.
- Update, retrain, or fine-tune the model as needed to maintain high performance.
This stage ensures that machine learning operations remain robust, scalable, and adaptable to changing business requirements.
Difference Between MLOps Vs DevOps
Although DevOps and MLOps (Machine Learning Operations) share the same objective of simplifying processes for efficacy improvement, their emphasis is totally different. DevOps mainly caters to software/application development; on the other hand, MLOps are designed considering machine learning models and data-driven systems. It’s important to know the differing business needs when choosing a process so that we can simulate ways in which they fit against these goals.
| Aspect | DevOps | MLOps |
| Primary Goal | To accelerate software delivery through automation, collaboration, and continuous integration/deployment (CI/CD). | To streamline the end-to-end ML lifecycle — from data preparation and model training to deployment and monitoring. |
| Core Focus | Focused mainly on code, application performance, and infrastructure. | Focused mainly on data, model accuracy, and adaptability. |
| Iteration Cycle | Iterations are short and frequent (daily/weekly) for deploying software updates. | Iterations depend on data changes — retraining happens when new data, drift, or performance issues arise. |
| Tools & Frameworks | Uses CI/CD tools like Jenkins, GitHub Actions, Docker, and Kubernetes. | Uses ML-specific tools like Kubeflow, MLflow, TFX, SageMaker, and MLOps AWS services. |
| Team Involvement | Involves developers, testers, and operations engineers. | Involves data scientists, ML engineers, and DevOps engineers. |
| Scalability Needs | Focuses on scaling application servers, APIs, and infrastructure for end-users. | Focuses on scaling data pipelines, ML training, and model deployments. |
| Testing Approach | Software is tested through unit tests, integration tests, and regression tests. | ML models are tested through data validation, bias detection, model accuracy, drift detection, and A/B testing. |
| Deployment Style | Code is deployed as applications or microservices. | Models are deployed as prediction services, APIs, or batch inference jobs. |
| Version Control | Manages code versions through Git and CI/CD systems. | Manages data versions, model versions, and experiment tracking. |
| Failure Management | Rollbacks or patches are applied when code fails. | Requires retraining or fine-tuning when models fail due to drift, bias, or poor accuracy. |
| Monitoring Metrics | Monitors system uptime, latency, and errors. | Monitors model accuracy, precision, recall, F1-score, and data drift. |
Conclusion
MLOps (Machine Learning Operations) is not a nice-to-have, but a must-have for organizations that want to derive significant business benefits from their AI/ML initiatives. By taking the seams out between data science, engineering, and IT operations, MLOps ensures ML models elegantly transition from experiments to production, where they are scalable, reliable, and regulatory compliant. MLOps has more challenging requirements than DevOps: it's not enough in MLOps to just deliver code, but you'll also need to monitor your models, track data drift, and run retraining cycles.
In the context of businesses, embracing MLOps is more than just about making AI/ML Ops pipelines efficient – it’s about unlocking sustainable value from machine learning in day-to-day operations.















 Write us on:
Write us on:  Business queries:
Business queries:  HR:
HR: