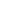Healthcare App Development Services
Healthcare App Development Services
 Real Estate Web Development Services
Real Estate Web Development Services
 E-Commerce App Development Services
E-Commerce App Development Services E-Commerce Web Development Services
E-Commerce Web Development Services Blockchain E-commerce Development Company
Blockchain E-commerce Development Company
 Fintech App Development Services
Fintech App Development Services Fintech Web Development
Fintech Web Development Blockchain Fintech Development Company
Blockchain Fintech Development Company
 E-Learning App Development Services
E-Learning App Development Services
 Restaurant App Development Company
Restaurant App Development Company
 Mobile Game Development Company
Mobile Game Development Company
 Travel App Development Company
Travel App Development Company
 Automotive Web Design
Automotive Web Design
 AI Traffic Management System
AI Traffic Management System
 AI Inventory Management Software
AI Inventory Management Software
 Machine Learning Development
Machine Learning Development ChatGPT integration services
ChatGPT integration services  AI Development Company
AI Development Company  AI Integration Services
AI Integration Services  Generative AI Development Services
Generative AI Development Services  Natural Language Processing Company
Natural Language Processing Company Mobile App Development
Mobile App Development  IOS App Development
IOS App Development  Android App Development
Android App Development  Cross-Platform App Development
Cross-Platform App Development  Augmented Reality (AR) App Development
Augmented Reality (AR) App Development  Virtual Reality (VR) App Development
Virtual Reality (VR) App Development  Web App Development
Web App Development  SaaS App Development
SaaS App Development Flutter
Flutter  React Native
React Native  Swift (IOS)
Swift (IOS)  Kotlin (Android)
Kotlin (Android)  Mean Stack Development
Mean Stack Development  AngularJS Development
AngularJS Development  MongoDB Development
MongoDB Development  Nodejs Development
Nodejs Development  Database Development
Database Development Ruby on Rails Development
Ruby on Rails Development Expressjs Development
Expressjs Development  Full Stack Development
Full Stack Development  Web Development Services
Web Development Services  Laravel Development
Laravel Development  LAMP Development
LAMP Development  Custom PHP Development
Custom PHP Development  .Net Development
.Net Development  User Experience Design Services
User Experience Design Services  User Interface Design Services
User Interface Design Services  Automated Testing
Automated Testing  Manual Testing
Manual Testing  Digital Marketing Services
Digital Marketing Services 
 Ride-Sharing And Taxi Services
Ride-Sharing And Taxi Services Food Delivery Services
Food Delivery Services Grocery Delivery Services
Grocery Delivery Services Transportation And Logistics
Transportation And Logistics Car Wash App
Car Wash App Home Services App
Home Services App ERP Development Services
ERP Development Services CMS Development Services
CMS Development Services LMS Development
LMS Development CRM Development
CRM Development DevOps Development Services
DevOps Development Services AI Business Solutions
AI Business Solutions AI Cloud Solutions
AI Cloud Solutions AI Chatbot Development
AI Chatbot Development API Development
API Development Blockchain Product Development
Blockchain Product Development Cryptocurrency Wallet Development
Cryptocurrency Wallet Development About Talentelgia
About Talentelgia  Our Team
Our Team  Our Culture
Our Culture 
 Healthcare App Development Services
Healthcare App Development Services Real Estate Web Development Services
Real Estate Web Development Services E-Commerce App Development Services
E-Commerce App Development Services E-Commerce Web Development Services
E-Commerce Web Development Services Blockchain E-commerce
Development Company
Blockchain E-commerce
Development Company Fintech App Development Services
Fintech App Development Services Finance Web Development
Finance Web Development Blockchain Fintech
Development Company
Blockchain Fintech
Development Company E-Learning App Development Services
E-Learning App Development Services Restaurant App Development Company
Restaurant App Development Company Mobile Game Development Company
Mobile Game Development Company Travel App Development Company
Travel App Development Company Automotive Web Design
Automotive Web Design AI Traffic Management System
AI Traffic Management System AI Inventory Management Software
AI Inventory Management Software AI Development Company
AI Development Company ChatGPT integration services
ChatGPT integration services AI Integration Services
AI Integration Services Machine Learning Development
Machine Learning Development Machine learning consulting services
Machine learning consulting services Blockchain Development
Blockchain Development Blockchain Software Development
Blockchain Software Development Smart contract development company
Smart contract development company NFT marketplace development services
NFT marketplace development services Asset tokenization companies
Asset tokenization companies DeFi Wallet Development Company
DeFi Wallet Development Company IOS App Development
IOS App Development Android App Development
Android App Development Cross-Platform App Development
Cross-Platform App Development Augmented Reality (AR) App
Development
Augmented Reality (AR) App
Development Virtual Reality (VR) App Development
Virtual Reality (VR) App Development Web App Development
Web App Development Flutter
Flutter React
Native
React
Native Swift
(IOS)
Swift
(IOS) Kotlin (Android)
Kotlin (Android) MEAN Stack Development
MEAN Stack Development AngularJS Development
AngularJS Development MongoDB Development
MongoDB Development Nodejs Development
Nodejs Development Database development services
Database development services Expressjs Development
Expressjs Development Full Stack Development
Full Stack Development Web Development Services
Web Development Services Laravel Development
Laravel Development LAMP
Development
LAMP
Development Custom PHP Development
Custom PHP Development User Experience Design Services
User Experience Design Services User Interface Design Services
User Interface Design Services Automated Testing
Automated Testing Manual
Testing
Manual
Testing About Talentelgia
About Talentelgia Our Team
Our Team Our Culture
Our Culture
Generative AI is leading the way in what might be described as the next digital revolution — one in which machines write, design, compose, and even create entire virtual worlds. As powerful new models in generative AI come to market and potential use cases are explored, organizations in various sectors are striving to access the capabilities inherent in this path-changing technology, from creating personalized content to producing synthetic media and automating complex tasks.
As per McKinsey, generative AI may contribute $4.4 trillion a year to the global economy, highlighting the fact that the future potential of generative AI can help make growth and innovation possible.
However, building a generative AI solution is much more than just plugging in an API or training a model. It encompasses a full-cycle approach, from data collection to algorithm selection, to deployment, testing, and continuous optimization.
In this blog, we’ll cover what generative AI is, the fundamental tech stack, the various stages of development, best practices, and the cost considerations. This way, you will be prepared to build, but build good, scalable, impactful solutions. Let’s get started:
What is Generative AI?
Generative AI— or gen AI for short— is a revolutionary artificial intelligence that allows machines to produce new media. Generative AI systems learn from a vast amount of existing data to create original content in various formats, be it human-like prose, impressive images, realistic videos, audio recordings, or software code.
Central to generative AI are sophisticated deep learning algorithms models inspired by the human brain. These AI systems are trained on huge amounts of data and specialized at identifying patterns, making predictions, and generating new content that bears similarities to the data they have been exposed to. When a user submits a request (like a natural language query), the AI interprets it and responds with new, contextually relevant content.
Generative AI holds incalculable potential in today’s business. Years of internal workflows, automating repetitive tasks, product development, and customer experiences are reimagined by the use of gen AI within organizations to innovate and gain efficiency. Thus far, nearly a third of organizations are already deploying generative AI in one or more core business functions, according to McKinsey & Company. Additionally, research and consulting firm Gartner predicts that more than 80% of enterprise companies will have integrated generative AI tools or APIs into their business practices by 2026.
While there are challenges and ethical concerns — including data privacy, misinformation, and model bias — generative AI is on the march. Companies that jump on this opportunity early are gearing themselves up for success in a fast-changing digital economy.
Steps To Build A Generative AI Solution
Building a generative AI solution isn’t just about choosing the right generative AI model—it’s about strategically combining data, tools, and development practices. Below is a step-by-step breakdown of how to develop a generative AI solution, from ideation to post-launch.
1. Defining the Problem and Setting Clear Objectives
Each successful generative AI development project begins with a key step: finding a clear problem to solve and putting it in line with clear business or product goals. This formative stage is where vision meets execution, and doing it well lays the groundwork for the rest of the solution lifecycle.
A. Understand the Core Challenge: The first decision you need to make before writing a single line of code or collecting a single data point is what problem your generative AI solution is going to solve. This move is not only about tech — it’s about purpose. Ask yourself:
- Are we trying to generate human-like text for chatbots or content platforms?
- Do we need to produce hyper-realistic images or art in a particular style?
- Is the goal to synthesize music, design layouts, or write code?
Each of these goals requires a different generative architecture, data preparation approach, and evaluation approach. More clarity on your problem statement will help you achieve a better outcome.
Pro Tip: The best thing you can do is to use a tool such as a problem framing worksheet to help define your user need, domain constraints, and desired use-case scope.
B. Detailing the Expected Outcome: Now that you’ve conquered the “what” and “why” of your project, it’s time to outline how it should look. This includes specifics like:
- For text-based AI: Language, tone, depth of context, writing style (e.g., technical vs. conversational).
- For image generation: Resolution, color schemes, artistic filters, dimensions, or thematic constraints.
- For music/audio: Genre, tempo, instruments, or emotional tone.
The more detailed your output expectations, the more efficiently you can choose the right data sources and model architectures.
C. Understand The Technology Stack
With your problem defined and the outputs scoped, spend some time exploring the generative AI architectures that will best satisfy your needs:
- Text generation tasks: GPT, BERT, or T5 transformer models are perfect for generating coherent, context-dependent language.
- Image generation: Try GANs (Generative Adversarial Networks) or VAEs (Variational Autoencoders) for creative visuals.
- Sequential data like music or time-series: RNNs and LSTMs (or even transformer-based audio models) are a better fit.
No matter how powerful, every AI model has its limits. Being cognizant of these from the outset helps to avoid misaligned expectations.
D. Know The Limits & Play To The Strengths: No matter how powerful, every AI model has its limits. Being cognizant of these from the outset helps to avoid misaligned expectations.
GPT-4 or GPT-3 is great for generating conversations or teaching, but might struggle with long-form consistency or factual accuracy.
While GANs can generate stunning artwork, they can yield erratic results without fine-tuning.
Knowing the capabilities and limitations of the mapping upfront allows for smarter decisions on model selection, tuning, and post-processing.
2. Data Collection
Before any generative AI model begins to learn, it needs fuel, and that fuel is data. Data collection is the most important part of any AI project, If you do this part correctly, you can successfully create any AI project. It doesn’t matter if you’re generating text, images, audio, or something completely different; your model is only as good as the dataset it learns from.
Here’s a breakdown of how to get it right:
A. The Right Data Sources are the Building Blocks
The first step is to know the source of your data. You may have structured curation sources, such as internal databases and APIs, or unstructured sources, such as web scraping, user-generated content, documents, or media files. Certain projects may use open datasets, while others may use proprietary or crowdsourced data. All in all, the source you choose must align with your use case and ensure rich, authentic content that mirrors real-world scenarios.
B. Focus on the diversity and volume of your data
Generative AI does best on diversity. This means that the more diverse your dataset is, the better your model’s performance under different conditions and prompts. If you are trying to build a text-generation model, include a wide variety of writing styles, tones, and dialects. If you are generating images, gather images from different resolution levels, lighting scenarios, and angles. Diversity is what allows your model to produce realistic, contextually relevant outputs for a broad suite of inputs.
C. Emphasis on Quality and Relevance
Not all data is good data. Gather data only relevant to what your model is trying to achieve. Noisy data or irrelevant data can result in bad results, hallucinations, or model bias. Automate as much as you can with human review loops for where it matters to maintain high data quality standards. Remember: no accurate data, no accurate answers.
D. Data Cleaning and Preprocessing
Data must be cleaned and preprocessed before it can be fed to your model. This includes:
- Cleaning duplicates and inconsistencies
- Handling missing values
- Filtering Out Irrelevant/Low-Quality Samples
- Standardizing the data format
For example, text often needs to be tokenized and normalized, and images often need to be resized, cropped, or pixel-normalized. This preprocessing makes sure that your model can physically read the input; the model learns faster and produces better output.
E. Ethical Compliance & Legal Considerations
- Copyrighted Content: Always use licensed, royalty-free, or original content.
- Case of sensitive or personal data: Do not process any data that is against privacy laws or ethical limitations.
- Regulations: Follow the data laws (like GDPR for Europe, CCPA for California, or any local rules).
It is important to ensure that user data is anonymized, encrypted during storage, and transferred safely in all environments. Proceed always with permissions if you collect any information.
F. Optimize with Labeling and Annotation
For supervised tasks, labeled data is gold. Techniques like active learning, semi-supervised learning, and crowdsourced labeling can make the annotation process faster and more affordable. Accurate labeling allows your model to learn specific features effectively, whether it’s tagging image objects or classifying text sentiment.
G. Organize with Data Splits and Storage
Divide your dataset into:
- Training set — to show patterns and structures to the model
- Validation set – to adjust the hyperparameters of the model and to benchmark interim performance
- Test set – to measure the real-world accuracy of the final model
Then, go with data storage that is scalable, secure , and accessible. It could be that you were using cloud-based platforms (AWS S3, Azure Blob Storage, or even private data warehouses) to manage large datasets with versioning, ease of collaboration, etc.
3. Data Processing
With the right data collected, you need to roll up your sleeves and set it up for your generative AI model. This step is akin to cleaning, organizing, and enriching raw ingredients before preparing a gourmet dish. It is proper data processing and labeling that differentiates the model that stumbles from the model that shines.
Now, let’s see how you make it model-ready.
A. Clean The Data, Remove The Noise
Real-world data is messy. It may contain missing values, duplicates, outliers, or formatting inconsistencies. This is where data cleaning comes into play, and with tools such as Pandas in Python, you can:
- Imputation or removal of missing entries
- Eliminate outliers or noise
- Fix spelling mistakes in the text
- Fix characters that do not display properly, such as emojis or HTML tags
- Standardize formats (for example, dates, currencies, units)
That also entails lowercasing, removing stopwords, and fixing typos in the case of text data for consistency.
B. Normalize & Standardize The Features
Raw data certainly has a lot of scale discrepancy. For instance, one column could span values from 1–1000, and another from 0–1. These variations can compound the learning if not corrected.
Use techniques like:
- Min-Max Normalization (scales data between 0 and 1)
- Z-score Standardization (centered around mean 0 and standard deviation 1)
This ensures that no single feature dominates simply because of its scale.
C. Boost Variety With Data Augmentation
To make your model more robust and less prone to overfitting, augment your dataset. This involves artificially expanding it by introducing smart variations.
- Image data: Rotate, zoom, crop, change brightness, or flip images
- Text data: Use synonym replacement, back-translation, or shuffle sentence structure
- Audio data: Add noise, change pitch, or speed
Augmentation introduces new perspectives, helping the model learn better generalizations.
D. Feature Extraction & Feeding
Before feeding features to the model, raw data needs to be properly transformed.
- Text: This involves tokenizing, stemming, lemmatization, or generating word embeddings such as Word2Vec, GloVe, or BERT
- Image: Edge detection or color histograms, or even feature maps
- Audio: Pull the spectral features out, such as MFC, for voice/music analysis
It allows the model to focus on the important stuff and improves its holistic understanding, which, in return, raises the performance.
E. Data Splitting
Your model can’t learn everything from one dataset. This is why it’s important to divide your dataset into:
- Training set: The data you will use to train the model
- Validation set: For hyperparameter tuning, interim testing
- Test set: For evaluating performance on unseen data
This practice reduces overfitting and allows for assessing how accurately the model generalizes.
F. Label The Data (Accurately)
Your data should have accurate labels for supervised learning tasks. These are the “answers” that your model will learn from.
Examples include:
- Object classification — tagging images with what objects they contain
- Sentiment classification from text
- Annotate audio for language or speaker recognition
You could label data in-house, using a platform like Amazon Mechanical Turk to do that for you, or semi-automatically have the model pre-label data, which humans verify. Keep in mind, if you label too poorly, even the best model will not perform well.
G. Maintain Data Consistency
The chronological order of the observations must be kept in a time series or sequential data. Ensure:
- Proper timestamp alignment
- Sorted entries
- Gaps filled (via interpolation, if necessary)
This is particularly relevant in areas such as stock prediction, IoT, or any time-dependent model.
H. Transforming Text into Edges (For NLP Tasks)
Words need to be converted into numerical representations, called embeddings, for natural language tasks.
Popular options include:
- GloVe
- FastText
- And other transformer-based models like BERT
Embeddings are able to capture well-developed context and semantic and syntactic relationships among words, making them an attractive choice for generative tasks such as summarizing text or creating a chatbot.
All in all, Data processing and labeling are more than technical steps; they are strategic moves. When done correctly, they take raw, messy data and transform it into a catalyst that drives your generative AI to produce results that are smarter, faster, and more reliable.
4. Building A Foundational Model
A foundation model is an AI model (word, visuals, or code) that has been pre-trained on very large datasets. You aren’t starting from square one because these models are preloaded with vast amounts of general knowledge and patterns.
Instead, you adapt them to your use, saving you time, money, and computing resources. Here is how you can choose the right foundational model:
A. Task Specificity
- GPT (like GPT-4): Fantastic for text generation, creative writing, chatbots, summarization, and even coding help. It scores in producing human-like, coherent content over extended conversations or documents.
- LLaMA 3: This model is more suitable for multilingual tasks. If your application involves multiple languages or even cultural contexts, then this model’s strengths in cross-lingual understanding are a big win.
- Mistral: Often regarded as a more lightweight, less resource-heavy choice, Mistral is a good candidate when you need concurrency, but your infrastructure just can’t handle heavy infrastructure.
- PaLM 2 / Google Gemini: These models seem to do better at reasoning, math, and logic-heavy tasks. If you’re making something that can benefit from smarter decisions or an awareness of context, you might want to look into them.
- DALL·E 2: A perfect platform for generating images from text prompts — a must-have for creatives, marketers, or product designers.
B. Dataset Compatibility
The type of data you have should match the model’s core training:
- If you’re working with text, go with models like GPT, LLaMA, or BERT.
- For image-based tasks, models like DALL·E or Stable Diffusion are more appropriate.
- For multi-modal tasks (text + image or audio), look into models that can handle more than one data type.
C. Model Size & Resource Requirement
Foundational models can be large, very large. Models such as GPT-4 use billions of parameters, which means high performance, but also high memory and GPU utilization
So, If you are constrained by local machines and budget cloud setups, try:
- Versions of the models scaled down (e.g., GPT-3.5 or LLaMA-2)
- Models tuned for edge devices or low-latency applications
It strikes a balance between performance and practical deployment.
D. Transfer Learning Capability
Certain models are good at transfer learning. They can take what they’ve learned from some generic training you do and then apply it to your specific task with minimal fine-tuning.
- BERT, for example, is often fine-tuned on only a few thousand examples to perform tasks such as sentiment analysis or entity recognition.
- GPT models are capable of adaptation through just a few prompts or a little additional training.
This is an amazing tool if you have a small labeled dataset, as these models have strong transfer learning capabilities.
6. Fine-Tuning & Retrieval-Augmented Generation (RAG)
After selecting your foundation model, the next most critical step is customizing that model for your specific requirements.” This is where Fine-Tuning & RAG (Retrieval-Augmented Generation) come to the rescue. These methods boost generative AI app performance, enabling the generation of context-based, precise, and high-quality responses.
Let’s outline them in a straightforward and actionable way.
A. Fine-Tuning AI Models
Fine-tuning is the process of taking a model that was pre-trained on a foundation (like GPT, BERT, or a vision model) and retraining it against a specific dataset or task. This fine-tuning helps the model better learn the nuances of your specific use case — whether that’s legal writing, customer service, medical diagnostics, or retail recommendations.
While the model architecture remains static, the internal weights of the model are learned and updated on your custom data to capture the patterns in your tone and writing style.
Here’s how to fine-tune a generative AI model effectively:
- Data Preparation & Cleaning – Make sure the dataset is well-formatted, tokenized, and preprocessed based on the respective tasks.
- Configure Output Layers – Alter the last layers of your model when you need them for unique outputs, such as classifications or labels.
- Differential Learning Rates – For Transformers, it is often possible through differential learning rates to fine-tune the model without losing the overall capabilities of the model.
- Avoiding overfitting – Using regularization methods (dropout, weight decay, etc.) to keep the model from performing well outside the training dataset.
Fine-tuning is ideal when your data has unique language, domain-specific jargon, or task-specific nuances that generic models might miss.
B. RAG
RAG is a potent hybrid approach that matches search capabilities with generative modeling. This makes it possible for a language model to retrieve relevant information from external sources (e.g., databases, documents, or knowledge bases) before generating a response.
That gives your AI system access in real-time to knowledge beyond what it learned from its training data, improving the accuracy, dynamism, and fact-checking of answers. Now, let’s look at the two phases of the RAG approach:
- Retrieval Phase: In this phase, the system looks through some sort of document store or knowledge base for information relevant to the user’s query. It makes use of advanced search techniques like:
- Semantic Search: Understands the true intent behind a search query instead of relying on mere keyword matching. For example, it understands that “tasty desserts” and “delicious sweets” are contextually similar.
- Embeddings (Vectorization): Models like BERT or GloVe transform both the text from the documents and the queries into a vector representation. These vectors exist in a high-dimensional space, where similar meanings cluster close together.
- Document Chunking: Large files are divided into smaller “chunks” based on topics or themes. This increases retrieval accuracy and guarantees that the model retrieves the most relevant segments for generation.
7. Deployment Phase
In AI development, deployment is more than simply getting to a live model, it’s a strategic step that determines long-term success. When deploying your generative AI solution at scale, you must set your sights beyond implementation and consider larger issues such as infrastructure readiness, data privacy compliance, model performance, and ethical usage.
In generative AI development, deployment is more than simply getting to a live model, it’s a strategic step that determines long-term success. When deploying your generative AI solution at scale, you must set your sights beyond implementation and consider larger issues such as infrastructure readiness, data privacy compliance, model performance, and ethical usage.
Here are some key principles to ensure a successful deployment:
- Deployment Environment: Based on your scalability and latency requirements, select the appropriate environment, which can be cloud, on-premise, or hybrid.
- Model Optimization: Optimize the model if necessary to achieve the best trade-off between performance and economic efficiency, particularly for large-scale inference.
- Interfaces: Define good-enough input and output interfaces while enabling consistent integration with user-facing applications.
- Security Measures: Ensure that you have secure protocols in place, from API development, security to data encryption and access controls, to keep the sensitive data safe.
- Monitoring & Feedback Loops: Implement real-time monitoring systems and user feedback mechanisms to identify and address issues promptly and improve outputs continuously.
8. Testing Phase
Given the widespread adoption of generative AI tools across industries ranging from healthcare and finance to creative design and customer service, the need for maintaining the ethical, legal, and functional integrity of these tools is non-negotiable. Regardless of whether you are a startup or an enterprise, testing your AI solution is a must-have step to ensure future risk mitigation, compliance, and real value for your users.
A structured testing strategy helps you predict how your generative AI product will perform in practice. Testing validates not just the precision and performance of the model but also its security and fairness, and ensures regulatory compliance, which is especially critical given the AI-conscious global marketplace we find ourselves in today.
To maintain high-quality standards throughout the lifecycle, consider integrating the following testing methods:
To ensure high standards across the lifecycle, implement the following testing methods:
- Unit Testing & Integration Testing: Test individual parts of your AI system to make sure that when they are combined, they work together correctly. This introduces the basis of finding functional bugs earlier in the system.
- Testing of Models (Accuracy, Bias, Cross Validation): Test your model for accuracy and generalization on different datasets regularly. This includes identifying and addressing biases that may creep into the model, as well as ensuring consistency and stability of the model against varying levels of input conditions.
- Performance and Stress Testing: Generative AI systems generally solve large-scale inference problems. Test your solution on peak load to see response time, system stability, and uptime. This allows your app to operate efficiently even in high-traffic or data-rich environments.
9. Post-Deployment Maintenance
Launching your generative AI application is a huge milestone—but it’s just the beginning, not the end. Deployment and the associated work is nothing but the first step; real work starts when you enter post-deployment maintenance. This stage involves constantly monitoring the performance of the models, recognizing new challenges, and adjusting the model to the user’s needs and the changing environment of data.
Post-launch oversight is especially important for generative AI. Unlike traditional software, AI systems can behave in unexpected ways once they see different data from the real world or receive new user inputs, or integrate with new platforms like third-party APIs or web browsers. Problems such as unexpected outputs, ethical issues, or biased responses frequently arise only after deployment.
A significant challenge to look out for is model drift. As the underlying data environment changes, though, the accuracy or relevance of the AI model may diminish, resulting in degraded performance. To prevent this, you need to:
- Learn to Track KPIs and Key Performance Metrics: Keep evaluating the model on set key performance indicators like accuracy, latency, relevancy, and user satisfaction.
- Keep track of Data Drift and Usage Patterns: Monitor for data drift or concept drift, which can impact the performance of the model and require further data collection for re-training/fine-tuning.
- Gather and Integrate Real-World Feedback: Reduce blindness and adjust for better outputs and more responsible behavior through user feedback and usage insights.
- Regular Model Updates: Update training datasets, revise prompts, and retrain your models to accommodate evolving needs and maintain long-term scalability and relevance.
So, in a nutshell, you cannot skip AI system maintenance — it’s an essential part of your product’s lifecycle. To keep your generative AI application efficient, ethical, and in line with business and user needs, it is also important to be proactive and iterative, even after it is deployed.
The Right Tech Stack For Building A Generative AI Solution
Finding the right tech stack is crucial in building a scalable, high-performing generative AI solution. Each of these layers is fundamental — from data preprocessing to deployment and performance tracking. Here’s the breakdown of the ideal tools and technologies for each category:
| Category | Recommended Tools | Why It Matters |
|---|---|---|
| Programming Language | Python | Dominates AI development for its simplicity, readability, and vast library ecosystem. |
| Deep Learning Framework | TensorFlow, PyTorch | Core frameworks for building, training, and scaling neural networks effectively. |
| Generative Models | GANs, VAEs | Enable generation of high-fidelity content such as images, audio, and synthetic text. |
| Data Processing | Pandas, NumPy, spaCy, NLTK | Handle data cleaning, transformation, and natural language preprocessing with ease. |
| GPU Acceleration | NVIDIA CUDA, cuDNN | Accelerate model training by enabling parallel computation and optimized processing. |
| Cloud Infrastructure | AWS, Google Cloud, Azure, IBM Cloud | Offer scalable storage, computing power, and AI-specific services for deployment. |
| Model Deployment | Docker, Kubernetes, Flask, FastAPI, TensorFlow Serving | Streamline deployment with scalability, portability, and robust API development. |
| Web Framework | Django, Flask, FastAPI | Build user-facing applications and RESTful APIs to connect users with GenAI outputs. |
| Database | PostgreSQL, MongoDB | Store and manage structured and unstructured data generated or used by AI models. |
| Automated Testing | PyTest | Ensure model accuracy, reliability, and performance through automated test scripts. |
| Visualization Tools | Matplotlib, Seaborn, Plotly | Visualize training data, loss metrics, and results to understand model performance. |
| Experiment Tracking | MLflow, TensorBoard | Keep track of experiments, hyperparameters, and performance metrics for optimization. |
| Image Processing | OpenCV, PIL | Handle image manipulation, preprocessing, and enhancement tasks for AI pipelines. |
| Version Control | GitHub, GitLab | Collaborate seamlessly and manage code versions effectively in AI projects. |
This modern generative AI tech stack is designed to cover every step of the generative AI development lifecycle—from model training to deployment and monitoring—ensuring optimal performance, maintainability, and scalability.
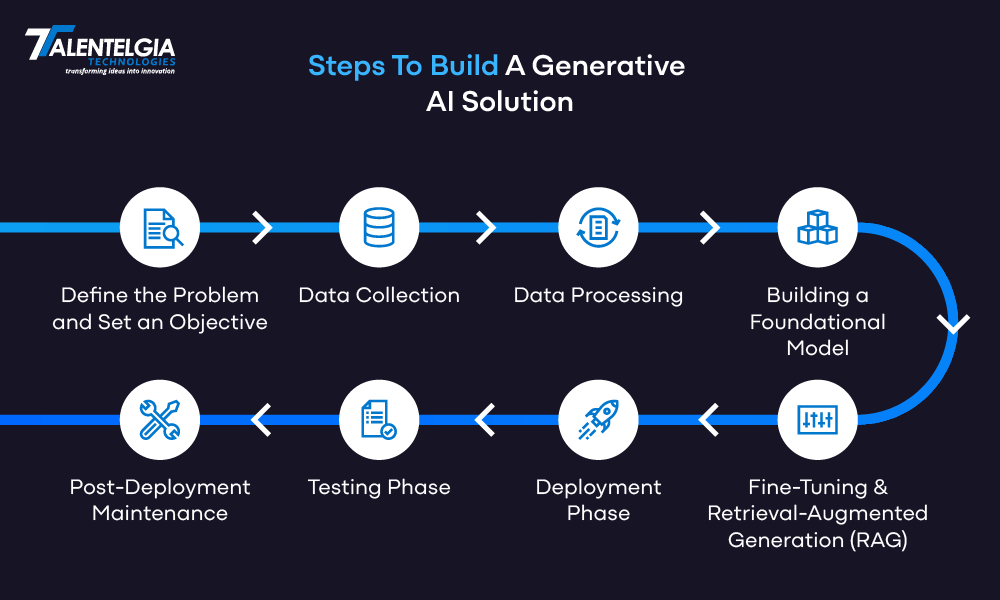
Best Practices For Building Generative AI Solutions
Creating a particularly impactful and efficient generative AI application involves more than just having great models, it involves strategic decisions at every step. Now, following proven best practices, you are on your way to creating AI solutions that perform well, are ethical, and lead to great user experiences.
Below are important best practices that can help guide your generative AI development journey:
1. Start with High-Quality, Clean Data
Your generative AI model output is only as good as the data it is trained on. Ensure that the data you gather is relevant, structured, unbiased, and error-free. This makes the dataset free of discrepancies and diverse, which makes the model produce correct and meaningful outputs. Only quality data can form the bedrock of reliable and strong AI rendering.
2. Choose the Right AI Models and Algorithms
Selecting the right model architecture is critical for achieving optimal results. For instance:
- Text generation? Transformer-based models like GPT-4 or LLaMA are ideal.
- Image synthesis? GANs or diffusion models work best.
- Code generation or summarization? Use task-specific fine-tuned LLMs.
Match your model to your use case to ensure your solution remains efficient, accurate, and scalable.
3. Ensure Data Privacy and Security
User data protection should be part of your development process from the very beginning. Adopt strong security protocols such as:
- End-to-end encryption
- User authentication and access control
- Regular vulnerability assessments
Not only that, but this helps in adhering to global data privacy regulations (such as GDPR and HIPAA) and establishes trust from the end-users who use your AI product.
4. The Fine-Tuning of Your Model for Accuracy
Out-of-the-box models are powerful, but tuning them to your specific task improves them substantially. Tune hyperparameters such as learning rate, batch size, number of epochs, and regularization techniques to enhance performance. It means that your AI outputs are contextual, high quality , and task-oriented because of such kind of fine-tuning.
5. Stay Updated With Evolving AI Ecosystem
Generative AI is a fast-evolving space, and developments continue to come thick and fast across model architectures, training methods, open-source libraries, and API capabilities. You must stay updated with all the latest advancements in the area so that your solution stays ahead and relevant. Moreover, it is important to stay up-to-date with regulatory changes to ensure compliance and avoid legal issues. Updating your generative AI System with new tech, better models, and improved optimization strategies periodically not only improves performance but also makes your AI product more secure and future-proof.
Conclusion
Generative AI is no longer some future reach — it’s here, rapidly evolving, and reshaping how companies think about creativity, efficiency, and personalization. Text generation, image synthesis, advanced code completion, even virtual assistants—the potential applications are endless, and are only limited by your imagination and strategy. However, creating a successful GenAI solution is not as simple as plugging into an API; it requires a careful approach, an appropriate tech stack, high-quality data, compliance, and a clearly defined use case.
Generative AI development today allows your business to pioneer innovation. And whether you’re developing from the ground up, or bolting on an AI component to existing services, ensuring that you remain true to best practice—both technical and ethical—will ensure that your solution is built upon the foundations it needs to scale responsibly, and create enduring impact. Are you ready to bring your GenAI vision to life? Let’s build it, smartly.















 Write us on:
Write us on:  Business queries:
Business queries:  HR:
HR: